Community Detection Using Spectral Clustering
Spectral Clustering
In the lecture on communities, we saw how to use the leading (first) eigenvector of the modularity matrix to split a network in two (and then split those partitions in two and so on).
Elsewhere, we saw that the eigendecomposition of a square matrix actually results in \(p\) eigenvectors and eigenvalues (not just the leading or first).
We also learned from the eigendecomposition lesson that selecting some number \(k < p\) of eigenvectors and eigenvalues helps us reconstruct the best approximation of the original matrix given that number of dimensions.
Putting these three lessons together suggests a simple way to detect multiple communities in a network using the eigenvalues of a suitable matrix, along with standard clustering algorithms such as k-means clustering. This approach does not have to iterate between binary divisions based on a single (leading) eigenvector, but can instead use multiple eigenvectors at once to partition the data into any desired number of clusters.
This general approach to community detection is sometimes referred to as spectral clustering.1
Spectral Clustering Using the Eigenvectors of the Laplacian
The issue then becomes, which matrix should we use the eigenvalues and eigenvectors of? As suggested by Von Luxburg (2007), an obvious candidate is what is called the graph Laplacian (\(\mathbf{L}\)), which is given by:
\[ \mathbf{L} = \mathbf{D} - \mathbf{A} \]
Where \(\mathbf{D}\) is the graph’s degree matrix a matrix with the degree vector of the graph along the diagonals and zeros everywhere else.
Like the modularity matrix, the \(\mathbf{L}\) matrix is doubly-centered (rows and columns sum to zero), which means, via some math other smarter people have worked out, that, if \(\mathbf{A}\) is connected, one of the eigenvalues of \(\mathbf{L}\) is guaranteed to be zero.2
The other interesting thing is that the second smallest (non-zero) eigenvalue of \(\mathbf{L}\) (sometimes called the Fiedler vector) provides an optimal (e.g., minimizing the number of cross-community edges) two-community partition of the graph (just like we saw the leading eigenvector of the modularity matrix does).
If we want to check for the existence of multiple groups, therefore, what we need to do is to create a new \(n \times k\) matrix \(\mathbf{U}\) composed of the \(k\) eigenvectors of \(\mathbf{L}\) associated with the \(k\) smallest eigenvalues, arranged from smallest to biggest.
We then normalize the node-specific row-vector of values of the\(\mathbf{U}\) matrix (e.g., using the Euclidean norm), and the use normalized \(\mathbf{U}\) matrix, which is an embedding of the node set of the graph in an k-dimensional Euclidean space, as input to a k-means algorithm with a known number of clusters (Fouss, Saerens, and Shimbo 2016, 320).
Let’s see how that would work. Let’s load the law_friends data from the networkdata package containing information on the friendship nominations of 68 lawyers in a firm. We have already analyzed these data using other community detection algorithms in a previous handout. The original data are directed, so we constrain them to be undirected and remove nodes with degree less than two:
We can then write a function called ratio.cut that accomplishes the eigendecomposition of the graph Laplacian matrix described earlier. It looks like this:
ratio.cut <- function(x, k = 6) {
A <- as.matrix(as_adjacency_matrix(x))
D <- diag(degree(x))
n <- vcount(x)
L <- D - A
eig.L <- eigen(L)
b <- n - k
e <- n - 1
U <- matrix(eig.L$vectors[, b:e], nrow = n, ncol = k)
if (k > 1) {
U <- U[, k:1] #re-ordering columns from smallest to biggest
}
for (i in 1:nrow(U)) {
U[i, ] <- U[i, ]/norm(as.matrix(U[i, ]), type = "E")
}
return(U)
}This function takes a graph as input and produces the \(\mathbf{U}\) matrix with \(n\) rows and \(k\) columns, with \(k=6\) by default. It first computes the adjacency matrix (line 2), then the degree matrix (line 3), then the Laplacian matrix (line 5). It then computes the eigendecomposition of the Laplacian (line 6), row normalizes the values taken by the eigenvectors corresponding to the \(k\) smallest eigenvalues in lines 10-13 (reverse-ordered from smallest to biggest in line 9), and returns the resulting matrix \(\mathbf{U}\) in line 14.
Let’s see the function at work:
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0.08 0.34 0.66 0.37 -0.54 0.13
[2,] 0.07 0.29 0.60 0.37 -0.53 0.37
[3,] 0.47 0.13 0.08 -0.87 0.03 0.04
[4,] 0.34 0.38 0.71 0.16 -0.45 0.10
[5,] 0.57 0.26 0.06 -0.78 0.00 0.01
[6,] 0.58 -0.76 -0.21 0.20 -0.05 0.03
[7,] 0.37 0.20 -0.01 -0.90 0.08 0.03
[8,] -0.02 0.33 0.65 0.41 -0.55 -0.01
[9,] 0.14 0.37 0.67 0.36 -0.52 0.04
[10,] 0.05 0.36 0.66 0.42 -0.50 0.06Which shows the corresponding values of \(\mathbf{U}\) for each node across the six eigenvectors of the Laplacian we selected.
Now, the basic idea is to treat each of the normalized scores along the six eigenvectors as if they were “variables” or “features” in a standard k-means clustering problem. The algorithm will then group nodes based on how similar their scores are on each six-dimensional vector. Similar nodes will correspond to communities (k-means clusters) in our data.
K-means clustering requires knowing how many groups we want in advance (differently from hierarchical clustering). Since we don’t know which is the best community partition beforehand, we instead compute a bunch of partitions and check the modularity of each.
The following function computes cluster assignments of the nodes in the graph up to ten partitions (starting from the minimum two):
This function takes the \(\mathbf{U}\) matrix as input and returns a nine-element list (with vectors of length \(n\) as its elements) of cluster assignments for each node in the graph, corresponding to partitions \(k = \{2, 3, \ldots 10\}\) respectively.
Let’s see the clustering function at work:
[[1]]
[1] 2 2 1 2 1 1 1 2 2 2 2 2 2 1 2 2 2 1 1 2 2 2 2 2 2 2 2 1 2 2 1 1 1 2 1 2 2 2
[39] 2 1 1 2 1 1 2 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[[2]]
[1] 3 3 1 3 1 1 1 3 3 3 3 3 3 1 3 3 3 1 1 3 3 3 3 3 3 3 3 1 3 3 1 1 1 3 1 3 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 3 2 2 2 2 1 1 1 1 2 1 2 2 2 2 2 2 2 2
[[3]]
[1] 3 3 4 3 4 4 4 3 3 3 3 3 3 4 3 3 3 4 1 3 3 3 3 3 3 3 3 4 3 3 4 4 4 3 1 3 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 3 2 2 2 1 1 1 1 1 2 4 2 2 2 2 2 2 2 2
[[4]]
[1] 3 3 5 3 5 5 5 3 3 3 3 3 3 5 3 3 3 5 1 3 3 3 3 3 3 3 3 5 3 4 4 4 4 3 1 3 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 3 2 2 2 1 1 1 1 1 2 4 2 2 2 2 2 2 2 2
[[5]]
[1] 3 3 5 3 5 5 5 3 3 3 3 3 3 5 3 3 3 5 1 3 3 3 3 3 4 3 3 5 3 4 6 6 6 3 1 4 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 3 2 2 2 1 1 1 1 1 2 6 2 2 2 2 2 2 2 2
[[6]]
[1] 3 3 5 3 5 5 5 3 3 3 3 3 3 5 3 3 3 5 1 3 3 3 3 3 4 3 3 5 3 4 6 6 6 3 1 4 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 3 2 2 2 1 1 1 1 1 2 6 7 2 7 7 7 7 7 7
[[7]]
[1] 8 8 5 8 5 5 5 8 8 8 8 8 8 5 8 8 8 5 1 8 8 8 8 8 4 8 8 5 8 4 6 6 6 3 1 3 3 3
[39] 3 2 2 3 2 1 3 2 1 1 2 8 2 2 2 1 1 1 1 1 2 6 7 2 7 7 7 7 7 7
[[8]]
[1] 8 8 5 8 5 5 5 8 8 8 8 8 8 5 8 8 8 5 1 8 8 8 8 8 4 8 8 5 8 4 6 6 6 3 1 3 3 3
[39] 3 2 2 3 7 1 3 2 1 1 2 8 2 2 2 7 1 1 1 1 7 6 7 2 9 9 9 9 9 9
[[9]]
[1] 3 3 5 3 5 5 5 3 3 3 3 3 3 5 8 3 3 5 1 3 3 3 3 3 4
[26] 3 3 5 3 4 6 6 6 10 1 10 10 10 10 2 2 10 7 1 10 2 1 1 2 8
[51] 2 2 2 7 1 1 1 1 7 6 7 2 9 9 9 9 9 9Great! Now that we have our partitions, we need to check the modularity corresponding to each one of them.
We can do this with the following quick function:
Which takes an igraph graph object and the list of cluster assignments as input and produces a vector of the same length as the list of cluster assignments with the modularity corresponding to that assignment.
Let’s see this function at work in our running example:
2 3 4 5 6 7 8 9 10
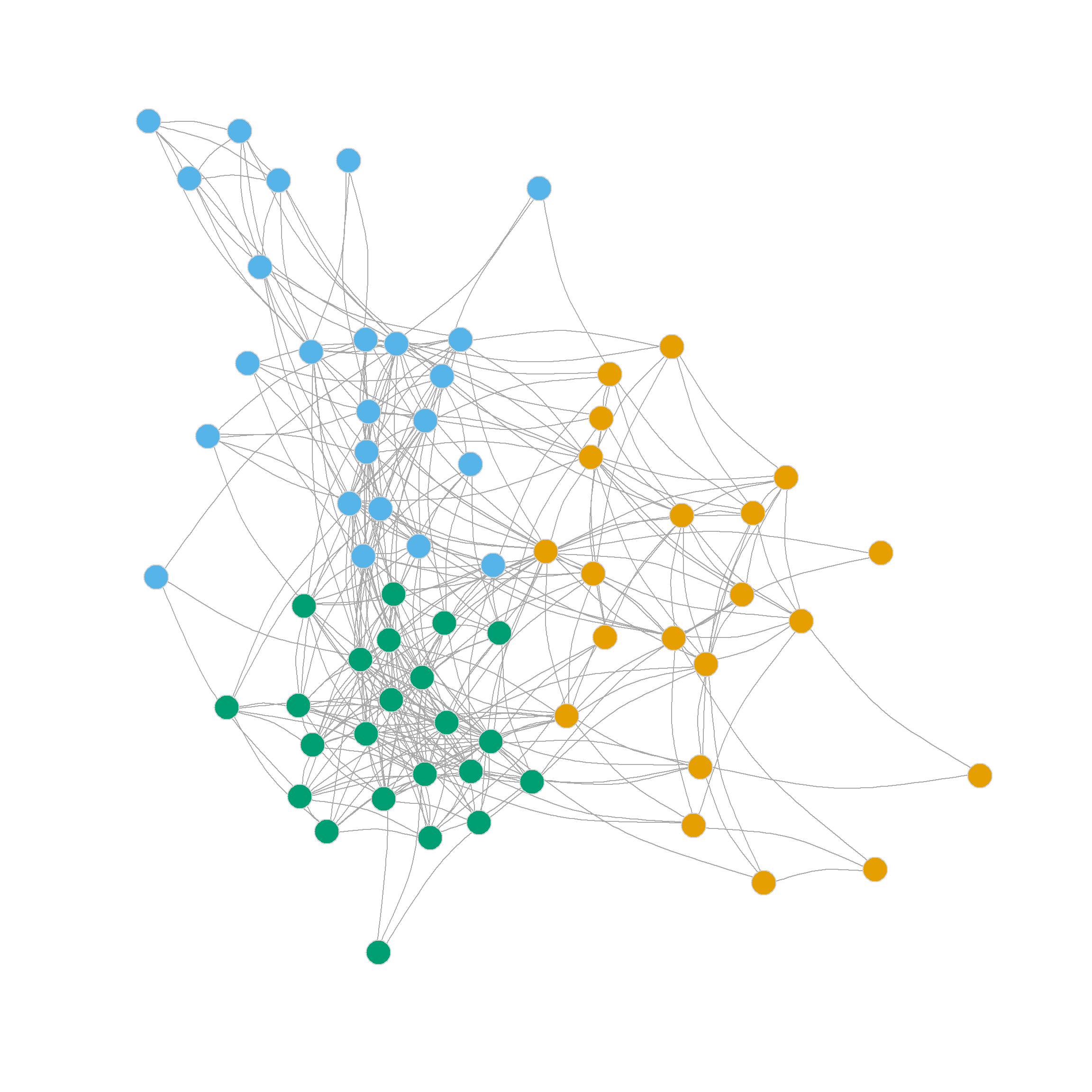
0.305 0.356 0.328 0.319 0.316 0.300 0.302 0.293 0.286 Which suggests that the three-cluster partition of the network (shown in Figure 1 (b)) does pretty well in separating densely connected subgraphs (\(Q = 0.36\)).
Note that this partition looks a lot like the one we settled on using Newman’s divisive leading eigenvector approach based on the modularity matrix: One core dense group of lawyers surrounded by a looser couple of communities.





Note also that the four, five, six and even seven-community partitions are not too shabby either. We can see those in Figure 1 (c)-Figure 1 (f) as they reveal further insights into the group structure of the network beyond the main three-community division.
Note that further subdivisions of the network split the more loosely structured community in the upper-right, while the more densely linked community in the lower-left remains largely undisturbed.
Spectral Clustering Using the Eigenvectors of the Normalized Laplacian
We saw how to cluster a network in a way that results in a good community partition using the Laplacian of the adjacency matrix \(\mathbf{L}\). Another approach is to use a (degree) normalized version of the same matrix \(\mathbf{\hat{L}}\), defined as follows:
\[ \mathbf{\hat{L}} = \mathbf{I} - \mathbf{D}^{-\frac{1}{2}}\mathbf{A}\mathbf{D}^{-\frac{1}{2}} \]
Where everything else is as before and \(\mathbf{I}\) is the identity matrix (an \(n \times n\) matrix with ones along the diagonals and zero everywhere else), and \(\mathbf{D}^{-\frac{1}{2}}\) is a matrix containing the inverse of the square root of degrees of each node (\(1/\sqrt{k_i}\)) in the diagonals and zeros everywhere else.
We can just adapt our previous ratio.cut function code to perform this new job:
norm.ratio.cut <- function(x, k = 6) {
A <- as.matrix(as_adjacency_matrix(x))
n <- vcount(x)
I <- diag(1, n, n)
D <- diag(1/sqrt(degree(x)))
L <- I - (D %*% A %*% D)
eig.L <- eigen(L)
b <- n - k
e <- n - 1
U <- matrix(eig.L$vectors[, b:e], nrow = n, ncol = k)
if (k > 1) {
U <- U[, k:1] #re-ordering columns from smallest to biggest
}
for (i in 1:nrow(U)) {
U[i, ] <- U[i, ]/norm(as.matrix(U[i, ]), type = "E")
}
return(U)
}Where we just have to modify the way we define the \(\mathbf{D}\) and \(\mathbf{L}\) matrices in lines 5 and 6 respectively, after creating the \(\mathbf{I}\) matrix in line 4.
Now let’s see if the normalized cut can help us finds some communities:
2 3 4 5 6 7 8 9 10
0.250 0.316 0.320 0.352 0.350 0.331 0.293 0.284 0.246 

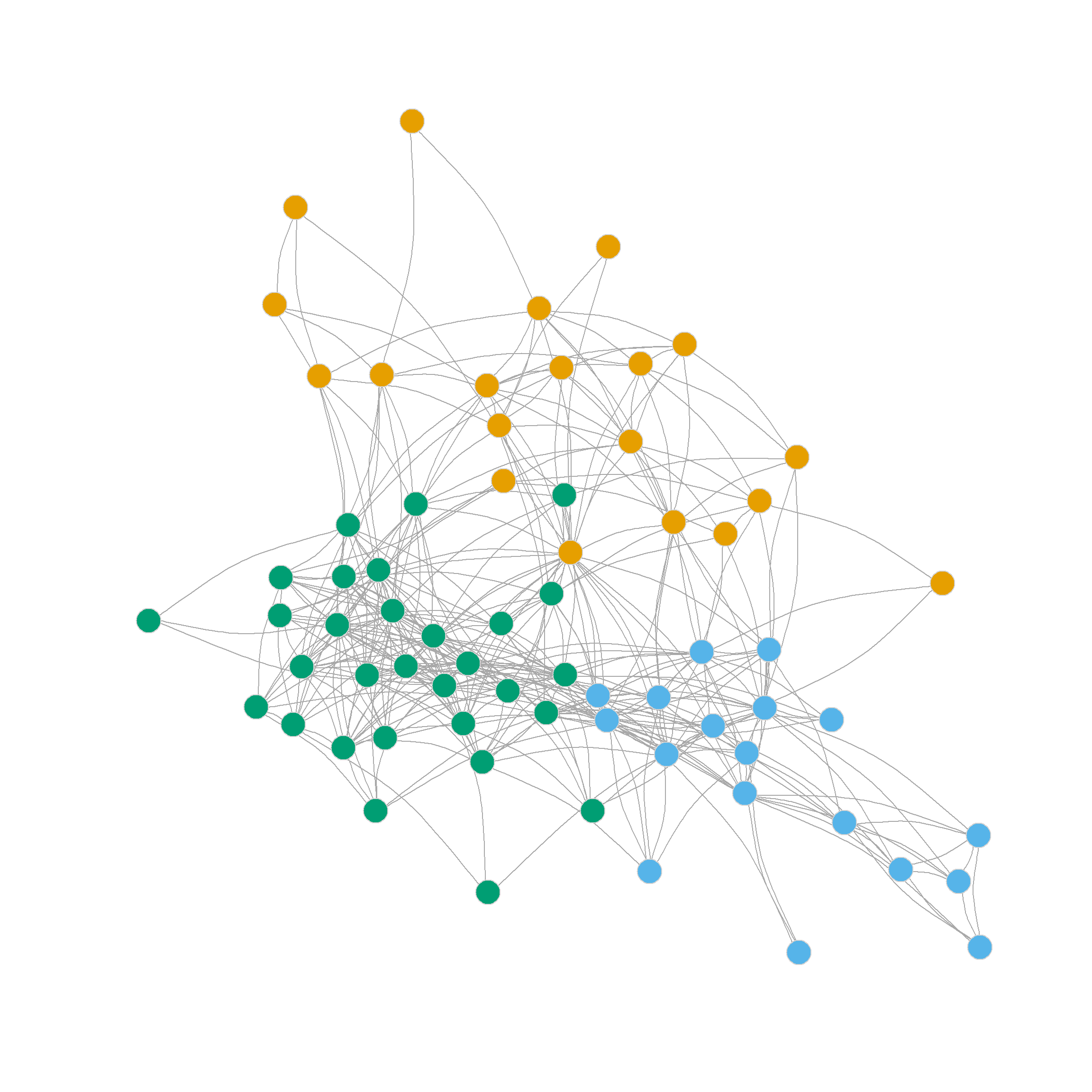
As we can see, the normalized ratio cut approach performs almost as well as the ratio cut approach in terms of the maximum modularity it finds (\(Q = 0.35\)), but suggests a finer grained partition, with the maximum at either five or six communities.
The resulting node clusters are shown in Figure 2 (a) and Figure 2 (b).
Spectral Clustering Using the Eigenvectors of the Degree-Normalized Laplacian
An alternative version of the normalized Laplacian is given by:
\[ \mathbf{\bar{L}} = \mathbf{D}^{-1}\mathbf{L} \]
Which is just the original Laplacian as defined earlier with each entry divided by the degree of the corresponding node in that row.
A function that extracts the relevant eigenvectors of this version of the normalized Laplacian goes as follows:
d.norm.ratio.cut <- function(x, k = 6) {
A <- as.matrix(as_adjacency_matrix(x))
n <- vcount(x)
I <- diag(1, n, n)
D <- diag(degree(x))
L <- solve(D) %*% (D - A)
eig.L <- eigen(L)
b <- n - k
e <- n - 1
U <- matrix(eig.L$vectors[, b:e], nrow = n, ncol = k)
if (k > 1) {
U <- U[, k:1] #re-ordering columns from smallest to biggest
}
for (i in 1:nrow(U)) {
U[i, ] <- U[i, ]/norm(as.matrix(U[i, ]), type = "E")
}
return(U)
}Where, once again, we only need to modify a couple of lines (5 and 6) from before to compute the new version of \(\mathbf{L}\).
To see the quality of the partitions obtained via this method, we just type:
2 3 4 5 6 7 8 9 10
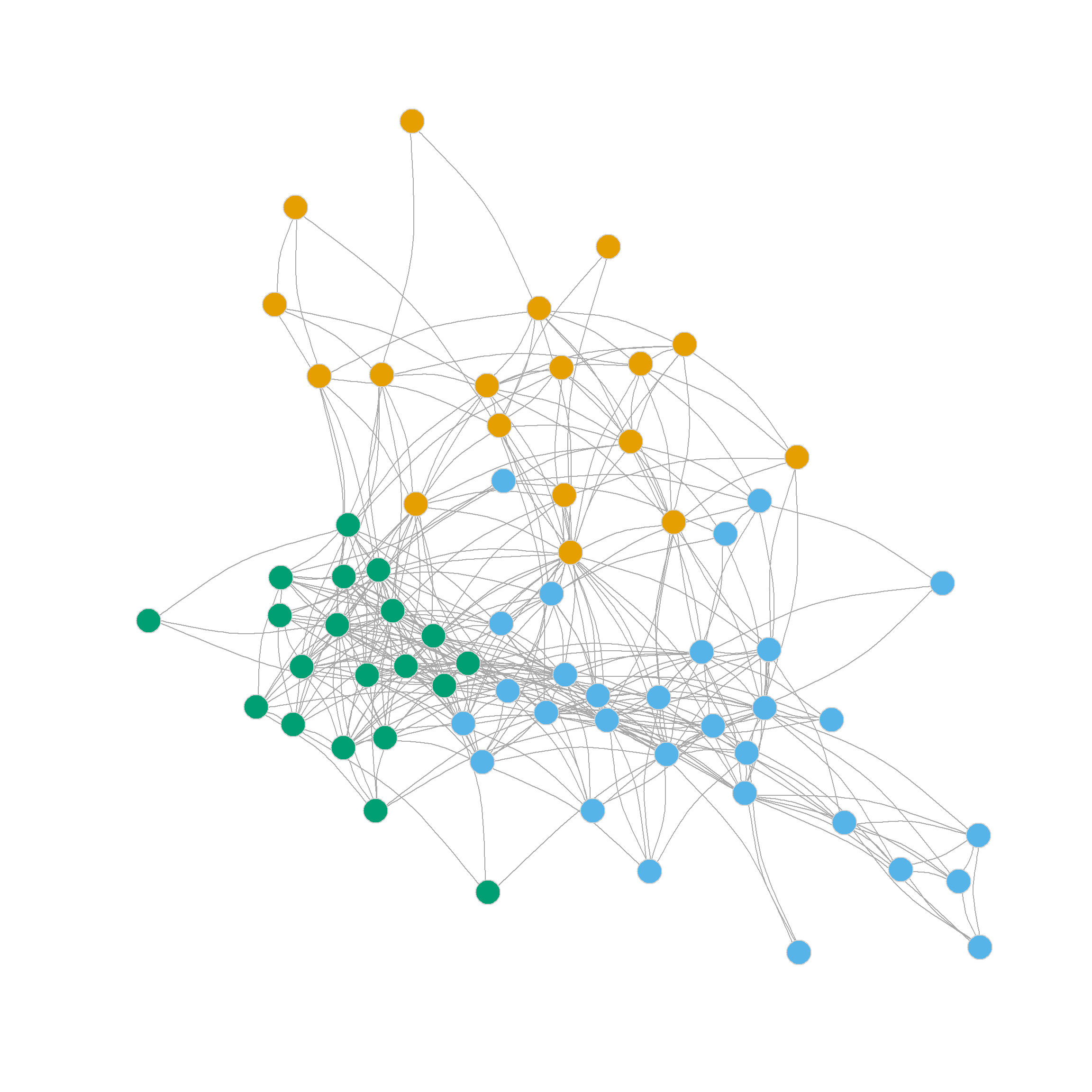
0.250 0.355 0.339 0.327 0.340 0.331 0.294 0.287 0.252 The degree-normalized Laplacian once again prefers the three-community partition, but also shows that the six community partition produces a high-quality clustering. Here’s how those look like:

Clustering Using the Eigenvectors of the Modularity Matrix
As noted by Fender et al. (2017, 1796), we can extend the spectral clustering approach based on the Laplacian and the normalized Laplacian to the modularity matrix \(\mathbf{B}\). That is, we cluster the graph by embedding the nodes in a set of dimensions defined by the eigendecomposition of \(\mathbf{B}\).
The main difference is that rather than using the eigenvectors corresponding to the smallest eigenvalues (as we did with \(\mathbf{L}\)) we proceed in more typical fashion (as done with PCA and CA) and choose the eigenvectors corresponding to the largest ones.
This approach, once again, only requires small modifications to the one we used for the Laplacian:
The key difference here is that we compute the modularity matrix \(\mathbf{B}\) rather than \(\mathbf{L}\) from the adjacency matrix \(\mathbf{A}\) in line 5; we then plug \(\mathbf{B}\) into the eigen function and proceed with normalizing in the same way as before.
Another difference is that rather than using a large number of eigenvalues (e.g., \(k = 6\)), as we did when we were picking from the smallest ones, we now go for parsimony and pick a small rank (two-dimensional) representation of the original modularity matrix (\(k = 2\)).
Let’s see how this works:
2 3 4 5 6 7 8 9 10
0.264 0.366 0.331 0.317 0.306 0.304 0.224 0.187 0.166 We can see that the three-cluster solution does really well modularity-wise (\(Q = 0.37\)), however, the four cluster solution also seems promising. The resulting communities are shown in Figure 3 (a) and Figure 3 (b).