As we noted in the role equivalence handout, for odd reasons, classical approaches to structural similarity in networks used distance metrics but did not measure similarity directly. More recent approaches from network and information science prefer to define vertex similarity using direct similarity measures based on local structural characteristics, like node neighborhoods.
Mathematically, similarity is a less stringent (but also less well-defined compared to distances) relation between pairs of nodes in a graph than distance, so it can be easier to work with in most applications.
For instance, similarity is required to be symmetric (\(s_{ij} = s_{ji}\) for all \(i\) and \(j\)) and most metrics have reasonable bounds (e.g., 0 for least similar and 1.0 for maximally similar). Given such a bounded similarity we can get to dissimilarity by subtracting one: \(d_{ij} = 1 - s_{ij}\)
Basic Ingredients of Vertex Similarity Metrics
Consider two nodes and the set of nodes that are the immediate neighbors to each. In this case, most vertex similarity measures will make use of three pieces of information:
The number of common neighbors \(p\).
The number of actors \(q\) who are connected to node \(i\) but not to node \(j\).
The number of actors \(r\) who are connected to node \(j\) but not to node \(i\).
In the simplest case of the binary undirected graph then these are given by:
library(networkdata)library(igraph) g.flint <- movie_267 g.flint <-delete_vertices(g.flint, degree(g.flint) <=3) A <-as.matrix(as_adjacency_matrix(g.flint)) A.p <- A %*% A #common neighbors matrix A.q <- A %*% (1- A) #neighbors of i not connected to j A.r <- (1- A) %*% A #neighbors of j not connected to i A.p[1:10, 1:10]
Note that while \(\mathbf{A}(p)\) is necessarily symmetric, neither \(q\) nor \(r\) have to be. Barney has many more neighbors that Bam-Bam is not connected to than vice versa. Also note that the \(\mathbf{A}(r)\) matrix is just the transpose of the \(\mathbf{A}(q)\) matrix in the undirected case.
So the most obvious measure of similarity between two nodes is simply the number of common neighbors (Leicht, Holme, and Newman 2006):
\[
s_{ij} = p_{ij}
\]
We have already seen a version of this in the directed case when talking about the HITS algorithm (Kleinberg 1999), which computes a spectral (eigenvector-based) ranking based on the matrices of common in and out-neighbors in a directed graph.
In this case, similarity can be measured either by the number of common in-neighbors or the number of common out-neighbors.
If the network under consideration is a (directed) citation network with nodes being papers and links between papers defined as a citation from paper \(i\) to paper \(j\), then the number of common in-neighbors between two papers is their co-citation similarity (the number of other papers that cite both papers), and the number of common out-neighbors is their bibliographic coupling similarity (the overlap in their list of references).
One problem with using unbounded quantities like the sheer number of common (in or out) neighbors to define node similarity is that they are only limited by the number of nodes in the network (Leicht, Holme, and Newman 2006). Thus, an actor with many neighbors will end up having lots of other neighbors in common with lots of other nodes, which will mean we would count them as “similar” to almost everyone.
Normalized Similarity Metrics
Normalized similarity metrics deal with this issue by adjusting the raw similarity based on \(p\) using the number of non-shared neighbors \(q\) and \(r\).
The two most popular versions of normalized vertex similarity scores are the Jaccard index and the cosine similarity (sometimes also referred to as the Salton Index).
The Jacccard index is given by:
\[
s_{ij} = \frac{p}{p + q + r}
\]
Which is the ratio of the size of the intersection of the neighborhoods of the two nodes (number of common neighbors) divided by the size of the union of the two neighborhoods.
Which is the ratio of the number of common neighbors divided by the product of the square root of the degrees of each node (or the square root of the product which is the same thing), since \(p\) + \(q\) is the degree of node \(i\) and \(p\) + \(r\) is the degree of node \(j\).
Showing results similar (pun intended) to those obtained using the Jaccard index.
A less commonly used option is the Dice Coefficient (sometimes called the Sorensen Index) given by:
\[
s_{ij} = \frac{2p}{2p + q + r}
\]
Which is given by the ratio of twice the number of common neighbors divided by twice the same quantity plus the sum of the non-shared neighbors (and thus a variation of the Jaccard measure).
Once again, showing results comparable to the previous.
Note, that all three of these pairwise measures of similarity are bounded between zero and one, with nodes being maximally similar to themselves and with pairs of distinct nodes being maximally similar when they have the same set of neighbors (e.g., they are structurally equivalent).
Leicht, Holme, and Newman (2006) introduce a variation on the theme of normalized structural similarity scores. Their point is that maybe we should care about nodes that are surprisingly similar given some suitable null model. They propose the configuration model as such a null model. This model takes a graph with the same degree distribution as the original but with connections formed at random as reference.
The LHN similarity index (for Leicht, Holme, and Newman) is then given by:
\[
s_{ij} = \frac{p}{(p + q)(p + r)}
\]
Which can be seen as a variation of the cosine similarity defined earlier.
Which, once again, produces similar results to what we found before. Note, however, that the LHN is not naturally maximal for self-similar nodes.
Similarity and Structural Equivalence
All normalized similarity measures bounded between zero and one (like Jaccard, Cosine, and Dice) also define a distance on each pair of nodes which is equal to one minus the similarity. So the cosine distance between two nodes is one minus the cosine similarity, and so on for the Jaccard and Dice indexes.
Because they define distances, this also means that these approaches can be used to find approximately structurally equivalent classes of nodes in a graph just like we did with the Euclidean and correlation distances.
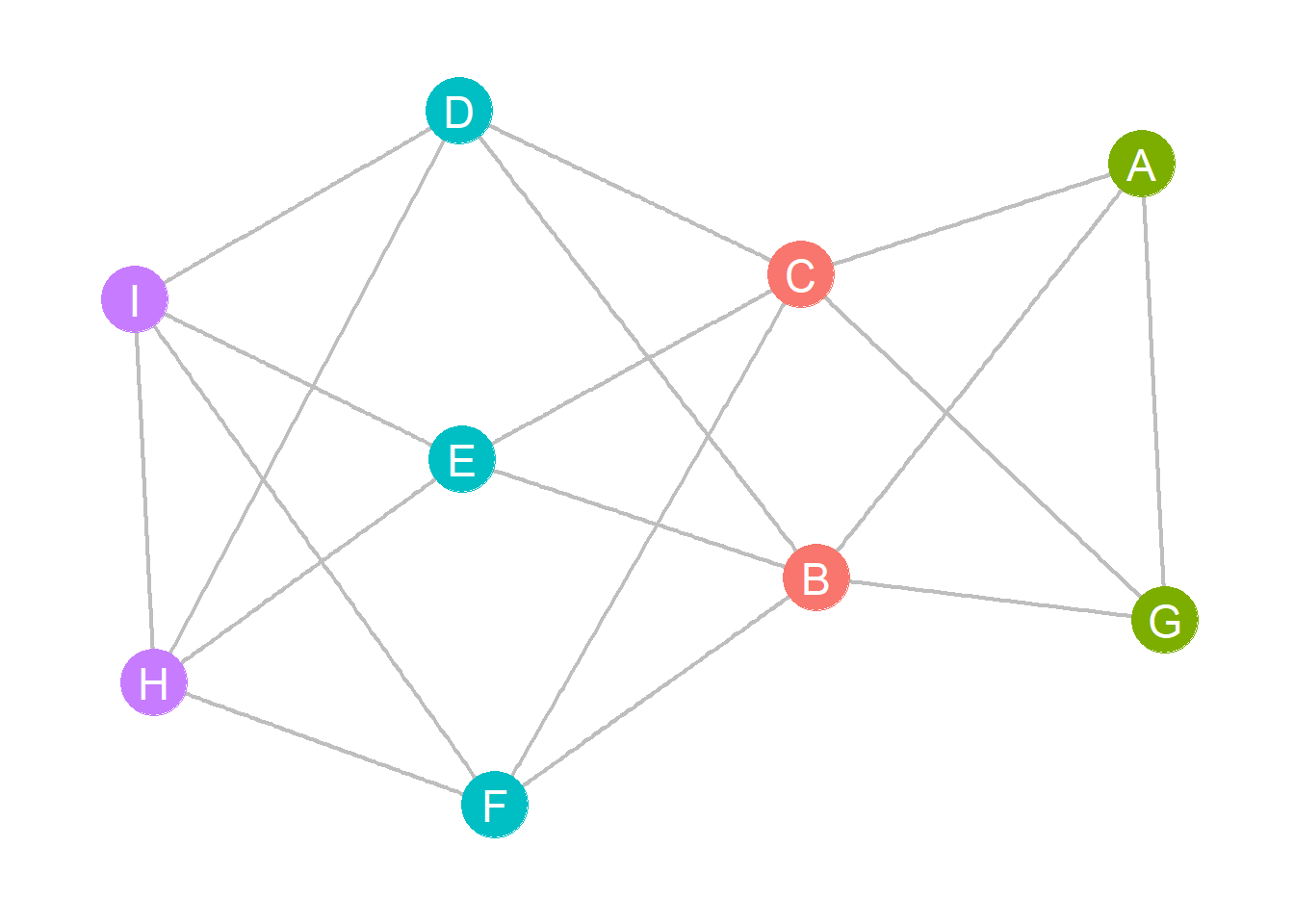
For instance, consider our toy graph from before with four structurally equivalent sets of nodes:
A toy graph demonstrating structural equivalence.
The cosine similarity matrix for this graph is:
A <-as.matrix(as_adjacency_matrix(g)) A.p <- A %*% A A.q <- A %*% (1- A) A.r <- (1- A) %*% A C <- A.p / (sqrt(A.p + A.q) *sqrt(A.p + A.r))round(C, 2)
A B C D E F G H I
A 1.00 0.26 0.26 0.58 0.58 0.58 0.67 0.00 0.00
B 0.26 1.00 1.00 0.00 0.00 0.00 0.26 0.67 0.67
C 0.26 1.00 1.00 0.00 0.00 0.00 0.26 0.67 0.67
D 0.58 0.00 0.00 1.00 1.00 1.00 0.58 0.25 0.25
E 0.58 0.00 0.00 1.00 1.00 1.00 0.58 0.25 0.25
F 0.58 0.00 0.00 1.00 1.00 1.00 0.58 0.25 0.25
G 0.67 0.26 0.26 0.58 0.58 0.58 1.00 0.00 0.00
H 0.00 0.67 0.67 0.25 0.25 0.25 0.00 1.00 0.75
I 0.00 0.67 0.67 0.25 0.25 0.25 0.00 0.75 1.00
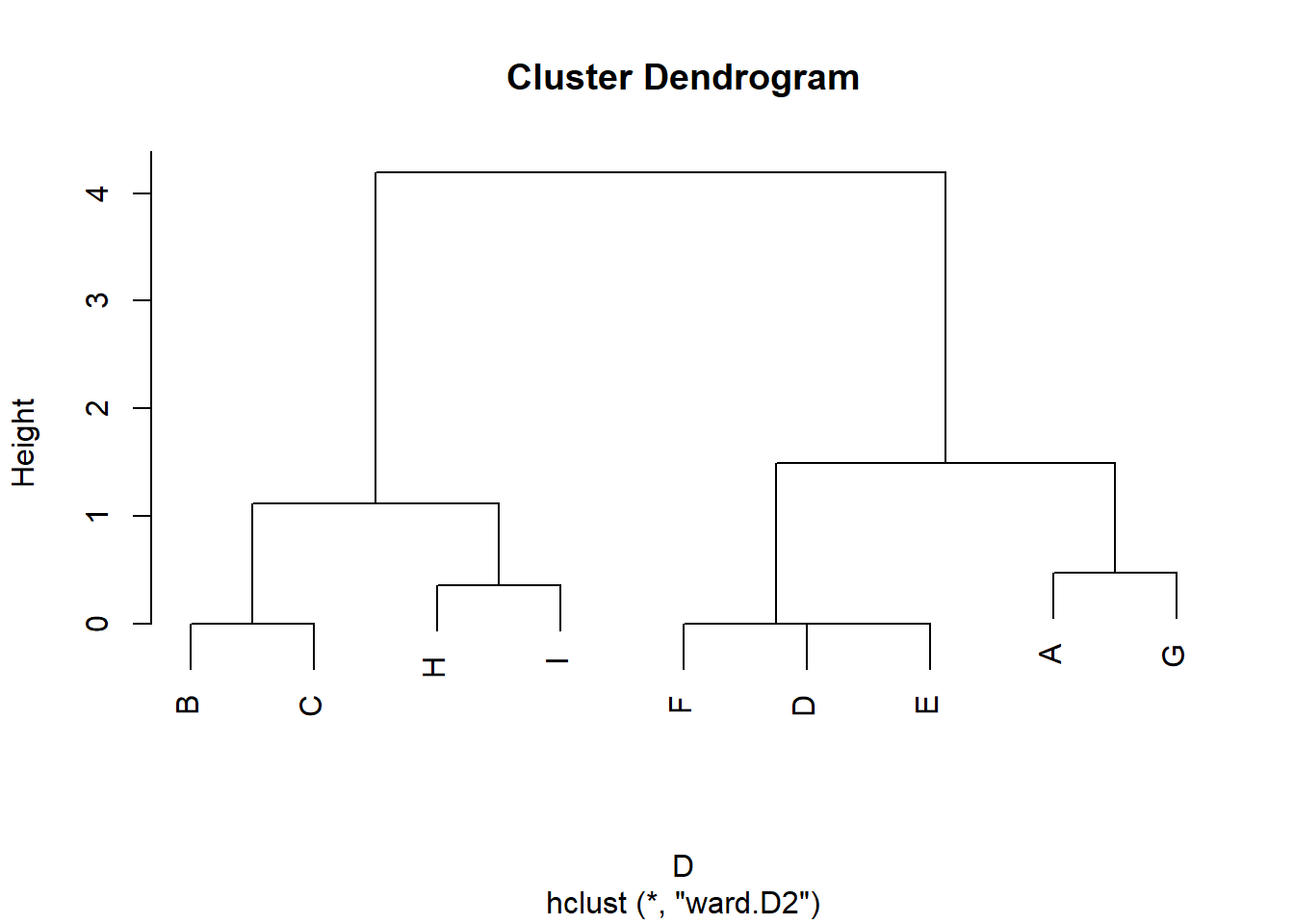
Note that structurally equivalent nodes have similarity scores equal to 1.0. In this case, the distance matrix is given by:
D <-1- C
And a hierarchical clustering on this matrix reveals the structurally equivalent classes:
D <-dist(D) h.res <-hclust(D, method ="ward.D2")plot(h.res)
We can package all that we said before into a handy function that takes a graph as input and returns all four normalized similarity metrics as output:
vertex.sim <-function(x) { A <-as.matrix(as_adjacency_matrix(x)) A.p <- A %*% A A.q <- A %*% (1- A) A.r <- (1- A) %*% A J <- A.p / (A.p + A.q + A.r) C <- A.p / (sqrt(A.p + A.q) *sqrt(A.p + A.r)) D <- (2* A.p) / ((2* A.p) + A.q + A.r) L <- A.p / ((A.p + A.q) * (A.p + A.r))return(list(J = J, C = C, D = D, L = L)) }
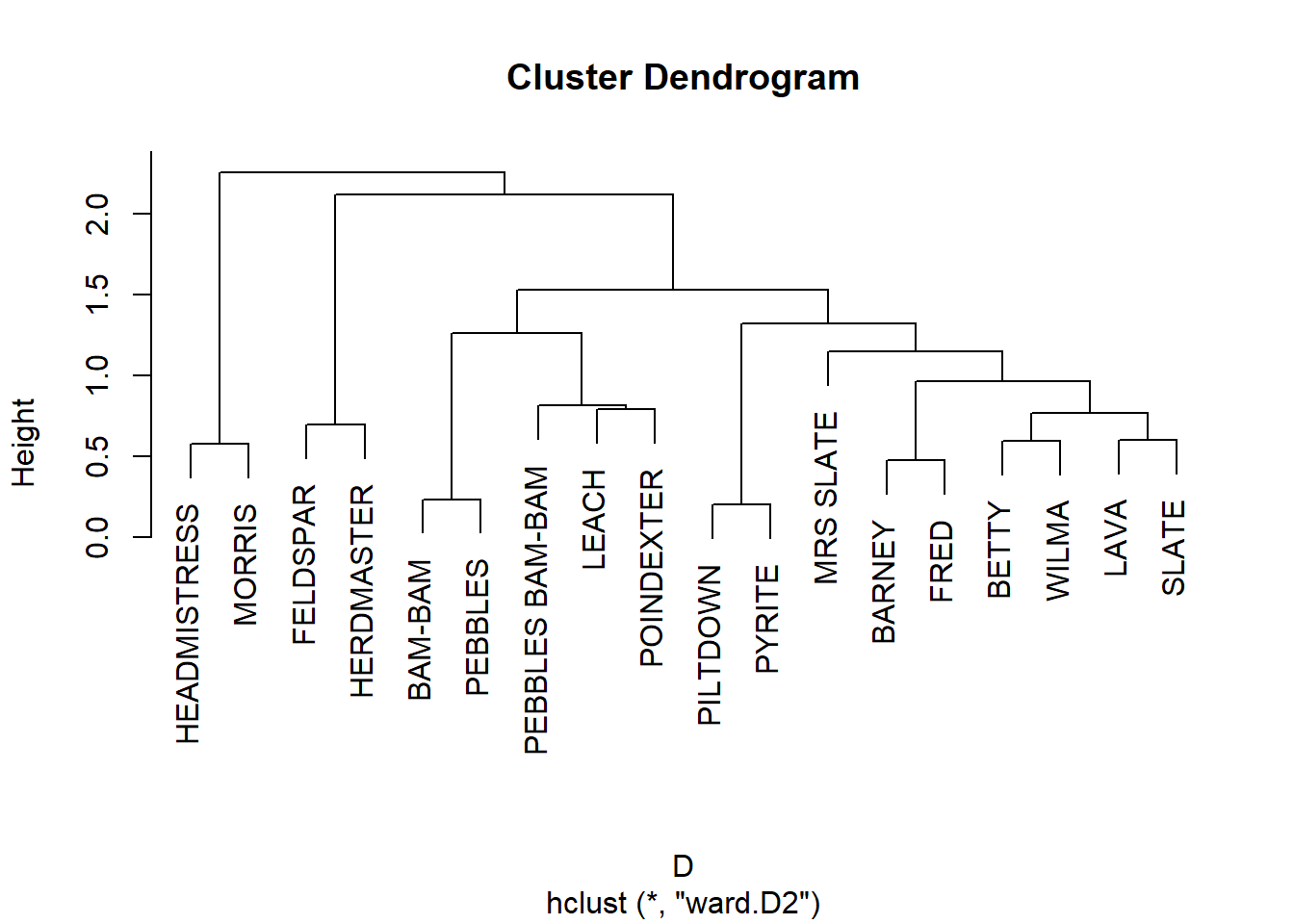
In the Flintstones network, we could then find structurally equivalent blocks from the similarity analysis as follows (using Cosine):
This analysis now puts \(\{Barney, Betty, Fred, Lava, Mrs. Slate, Slate, Wilma\}\) in the second block of equivalent actors (shown as the right-most cluster of actors in the dendrogram).
Generalized Similarities
So far, we have defined distances and similarities mainly as a function of the number of shared neighbors between two nodes. Structural equivalence is an idealized version of this, obtaining whenever people share exactly the same set of neighbors.
Yet, similarities based on local neighborhood information only have been criticized (e.g., by Borgatti and Everett (1992)) for not quite capturing the sociological intuition behind the idea of a role which is usually what they are deployed for. That is, two doctors don’t occupy the same role because they treat the same set of patients (in fact, this would be weird); instead, the set of doctors occupy the same role to the extent they treat a set of actors in the same (or similar) role: Namely, patients, regardless of whether those actors are literally the same or not.
This worry led social network analysts to try to generalize the concept of structural equivalence using less stringent algebraic definition, resulting in something of a proliferation of different equivalences such as automorphic or regular equivalence(Borgatti and Everett 1992).
Unfortunately, none of this work led (unlike the work on structural equivalence) to useful or actionable tools for data analysis, with some even concluding that some definitions of equivalence (like regular equivalence) are unlikely to be found in any interesting substantive setting.
A better approach here is to use the more relaxed notion of similarity like we did above to come up with a more general definition that can capture our role-based intuitions. Note that all the similarity notions studied earlier have structural equivalence as the limiting case of maximum similarity. So they are still based on the idea that nodes are similar to the extent they connect to the same others.
We can generalize this idea (to deal with the doctor/patient role problem) in the following way: nodes are similar to the extent they connect to similar others, with the restriction that we can only use endogenous (structural connectivity) information—like with structural equivalence or common-neighbor approaches—to define everyone’s similarity (no exogenous attribute stuff).
As Jeh and Widom (2002) note, this approach does lead to a coherent generalization of the idea of similarity for nodes in graphs because we can just define similarity recursively and iterate through the graph until the similarity scores stop changing.1 More specifically, they propose to measure the similarity between two nodes \(i\) and \(j\) at each time-step in the iteration using the formula:
So the similarity between two nodes at step \(t\) is just the sum of the pairwise similarities between each of their neighbors (computed in the previous step, \(t-1\)), weighted by the ratio of a free parameter \(\alpha\) (a number between zero and one) to the product of their degrees (to take a weighted average).
This measure nicely captures the idea that nodes are similar to the extent they both connect to people who are themselves similar. Note that it doesn’t matter whether these neighbors are shared between the two nodes (the summation occurs over each pair of nodes in \(p\) + \(q\) versus \(p\) + \(r\) as defined earlier) or whether the set of neighbors are themselves neighbors, which deals with the doctor/patient problem.
A function that implements this idea looks like:
SimRank.in <-function(A, C =0.8, iter =10) { d <-colSums(A) n <-nrow(A) S <-diag(1, n, n)rownames(S) <-rownames(A)colnames(S) <-colnames(A) m <-1while(m < iter) {for(i in1:n) {for(j in1:n) {if (i < j) { a <-names(which(A[, i] ==1)) b <-names(which(A[, j] ==1)) Sij <-0for (k in a) {for (l in b) { Sij <- Sij + S[k, l] #i's similarity to j } } S[i, j] <- C/(d[i] * d[j]) * Sij S[j, i] <- C/(d[i] * d[j]) * Sij } } } m <- m +1 }return(S)}
Note that this function calculates SimRank using each node’s in-neighbors (this doesn’t matter if the graph is undirected).
Let’s try it out in the Flintstones graph using \(\alpha = 0.95\):
A <-as.matrix(as_adjacency_matrix(g.flint)) S <-SimRank.in(A, 0.95)round(S[, 1:5], 2)
Which returns a somewhat different role partition than the metrics relying on structural equivalence. In the SimRank equivalence partition, \(\{Fred, Barney\}\) are in their own standalone class, while \(\{Betty, Wilma, Slate, Mrs. Slate, Lava\}\) appear as a separate cluster.
Global Similarity Indices
As we saw earlier, the most important ingredient of structural similarity measures between pairs of nodes is the number of common of neighbors (followed by the degrees of each node), and this quantity is given by the square of the adjacency matrix \(\mathbf{A}^2\). So we can say that this matrix gives us a basic similarity measure between nodes, namely, the common neighbors similarity:
\[
\mathbf{S} = \mathbf{A}^2
\]
Another way of seeing this is that a common neighbor defines a path of length two between a pair of nodes. So the number of common neighbors between two nodes is equivalent to the number of paths of length two between them. We are thus saying that the similarity between two nodes increases as the number of paths of length two between them increases, and that info is also recorded in the \(\mathbf{A}^2\) matrix.
The Local Path Similarity Index
But if the similarity between node pairs increases in the number of paths of length two between them, wouldn’t nodes be even more similar if they also have a bunch of paths of length three between them?
Lü, Jin, and Zhou (2009) asked themselves the same question and proposed the following as a similarity metric based on paths:
This is the so-called local path similarity index(Lü, Jin, and Zhou 2009). Obviously, structurally equivalent nodes will be counted as similar by this metric (lots of paths of length two between them) but also nodes indirectly connected by many paths of length three, but to a lesser extent given the discount parameter \(\alpha\) (a number between zero and one).
A function that does this is:
local.path <-function(A, alpha =0.5) { A2 <- A %*% A S <- A2 + alpha*(A2 %*% A)return(S) }
Here’s how the local path similarity looks in the Flintstones network:
A <-as.matrix(as_adjacency_matrix(g.flint)) S <-local.path(A) S[1:10, 1:10]
Of course as \(\alpha\) approaches zero, then the local path measure reduces to the number of common neighbors, while numbers closer to one count paths of length three more.
Another thing people may wonder if why not keep going and add paths of length four:
Where \(k\) is the length of the maximum path considered. Lü, Jin, and Zhou (2009) argue that these higher order paths don’t matter, so maybe we don’t have to worry about them.
The Katz Similarity
Another issue is that there was already an all-paths similarity measure in existence, one developed by the mathematical social scientist Leo Katz (1953) in the 1950s (!).
The basic idea was to use linear algebra tricks to solve:
Which would theoretically count the paths of all possible lengths between two nodes while discounting the contribution of the longer paths in proportion to their length (as \(k\) gets bigger, with \(\alpha\) a number between zero and one, \(\alpha^k\) gets smaller and smaller).
Linear algebra hocus-pocus (non-technical explainer here) turns the above infinite sum into the more tractable:
\[
\mathbf{S} = (\mathbf{I} - \alpha A)^{-1}
\]
Where \(\mathbf{I}\) is the identity matrix (a matrix of all zeros except that it has the number one in each diagonal cell) of the same dimensions as the original. Raising the result of the subtraction in parentheses to minus one indicates the matrix inverse operation (most matrices are invertible, unless they are weird).
A function to compute the Katz similarity between all node pairs is:
katz.sim <-function(A, min.alpha =0.05) { I <-diag(nrow(A)) #creating identity matrix alpha <-runif(1, min = min.alpha, max =1/eigen(A)$values[1]) S <-solve(I - alpha * A) return(S) }
For technical reasons (e.g., guarantee that the infinite sum converges) we need to choose \(\alpha\) to be a number larger than zero but smaller than the reciprocal of the first eigenvalue of the matrix. Hence we just pick a random value in that interval in line 3 (set the seed to get reproducible answers). Line 4 computes the actual Katz similarity using the native R function solve to find the relevant matrix inverse.2
In the Flintstones network the Katz similarity looks like:
set.seed(456) S <-katz.sim(A)round(S[1:10, 1:10], 2)
Leicht, Holme, and Newman (2006) argue that the Katz approach is fine and dandy as a similarity measure, but note that is an unweighted index (like the raw number of common neighbors). This means that nodes with large degree will end up being “similar” to a buch of other nodes in the graph, just because they have lots of paths of length whatever between them and those nodes.
Leicht, Holme, and Newman (2006) propose a “fix” for this weakness in the Katz similarity, resulting in the matrix linear algebra equivalent of a degree-normalized similarity measure like the Jaccard or Cosine.
Here \(\mathbf{D}\) is a matrix containing the degrees of each node along the diagonal. The inverse of this matrix \(\mathbf{D}^{-1}\) will contain the reciprocal of each degree \(1/k_i\) along the diagonals. \(\lambda_1\), on the other hand, is just the first eigenvalue of the adjacency matrix.
So, the LHN Similarity is just the Katz similarity weighted by the degree of the sender and receiver node along each path, further discounting paths featuring high-degree nodes at either or both ends.
Which leads to the function:
LHN.sim <-function(A, alpha =0.9) { D <-solve(diag(rowSums(A))) #inverse of degree matrix lambda <-eigen(A)$values[1] #first eigenvalue of adjacency matrix S <- D %*%solve((alpha * A)/lambda) %*% D #LHN indexrownames(S) <-rownames(A)colnames(S) <-colnames(A)return(S) }
Note that as Leicht, Holme, and Newman (2006) discuss, the entries in the LHN version of the similarity \(\mathbf{S}\) can be either positive or negative. Negative entries are nodes that are surprisingly dissimilar given their degrees, and positive numbers indicating node pairs that are surprisingly similar. Numbers closer to zero are nodes that are neither similar nor dissimilar given their degrees.
Here we can see that Barney and Fred are actually not that similar to one another (after we take into account their very high degree) and that Barney is actually most similar to Feldspar (and Fred even more so).
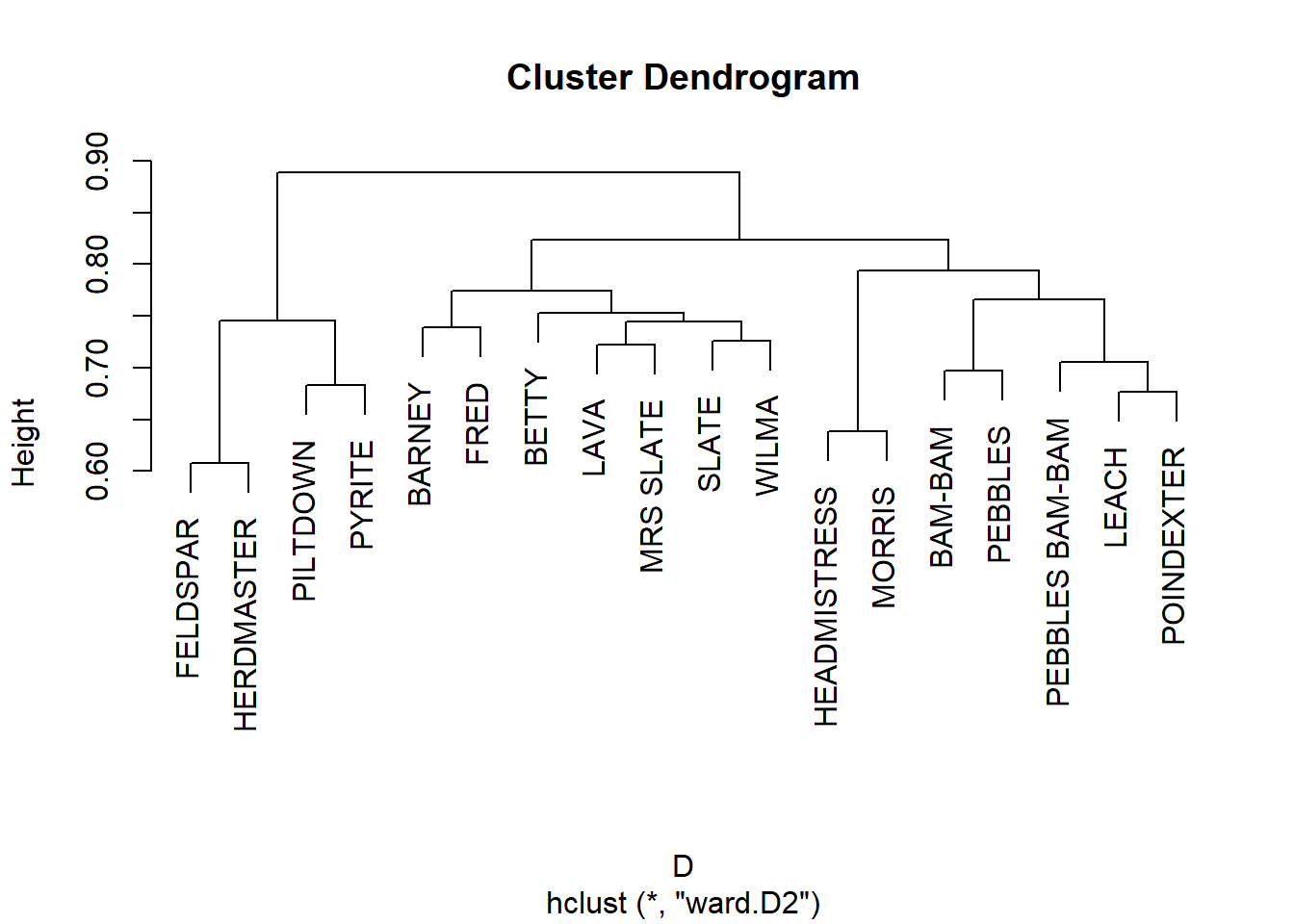
Because the LHN similarities have negative and positive values, they already define a distance between nodes in the graph, like the correlation distance. So if we wanted to find blocks of actors using this similarity criterion, all we need to do is:
D <-dist(S) h.res <-hclust(D, method ="ward.D2")plot(h.res)
It seems like this approach is geared towards finding smaller, more fine-grained clusters of similar actors in the data.
Appendix
A more general version of the function to compute SimRank looks like this (partly based on Fouss, Saerens, and Shimbo 2016, 84, algorithm 2.4):
SimRank <-function(A, sigma =0.0001, alpha =0.8) { n <-nrow(A) d <-as.numeric(colSums(A) >0) e <-matrix(1, n, 1) Q <-diag(as.vector(t(e) %*% A), n, n)diag(Q) <-1/diag(Q) Q <- A %*% Q Q[is.nan(Q)] <-0 diff <-1 k <-1 K <-diag(1, n, n)while(diff > sigma) { K.old <- K K.p <- alpha *t(Q) %*% K %*% Q K <- K.p -diag(as.vector(diag(K.p)), n, n) +diag(d, n, n) diff <-abs(sum(abs(K.old)) -sum(abs(K))) k <- k +1 }rownames(K) <-rownames(A)colnames(K) <-colnames(A)return(K) }
References
Borgatti, Stephen P, and Martin G Everett. 1992. “Notions of Position in Social Network Analysis.”Sociological Methodology 22: 1–35.
Fouss, François, Marco Saerens, and Masashi Shimbo. 2016. Algorithms and Models for Network Data and Link Analysis. Cambridge University Press.
Jeh, Glen, and Jennifer Widom. 2002. “Simrank: A Measure of Structural-Context Similarity.” In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 538–43.
Katz, Leo. 1953. “A New Status Index Derived from Sociometric Analysis.”Psychometrika 18 (1): 39–43.
Kleinberg, Jon M. 1999. “Authoritative Sources in a Hyperlinked Environment.”Journal of the ACM (JACM) 46 (5): 604–32.
Leicht, Elizabeth A, Petter Holme, and Mark EJ Newman. 2006. “Vertex Similarity in Networks.”Physical Review E—Statistical, Nonlinear, and Soft Matter Physics 73 (2): 026120.
Lü, Linyuan, Ci-Hang Jin, and Tao Zhou. 2009. “Similarity Index Based on Local Paths for Link Prediction of Complex Networks.”Phys. Rev. E 80: 046122.
Footnotes
Note the similarity (heh, heh) between this idea and the various status ranking algorithms we discussed in the previous handout.↩︎
See here for an explainer of the matrix inverse in general and its computation in R.↩︎