Statistical Models of Networks I
So far we have treated the observed ties in a given network as given, along with any metrics computed from those ties (e.g., attribute correlations, centralities, etc.). The idea of uncertainty around an estimate, foundational to traditional statistics, has so far not been applicable.
Another approach, and one that brings in concerns about inference, statistical significance, and so forth, is to think of the observed network data as a realization of some underlying random or probabilistic process.
Random Networks
There are many ways to go about this, but in the following handouts we will cover two important ones. First we can treat the whole network as a realization of some random process. That leads to models of random networks and graph ensembles (Orsini et al. 2015). This approach is useful for testing single hypotheses against a plausible null (e.g., are the levels of homophily that I am observing in this network more or less than we would expect by chance?). A variation of this strategy uses permutations to do a version of multiple regression in network data (Krackhardt 1988).
Second, there are models that treat each link in the network as a realization of some random process (Pattison and Robins 2002). Because a network is just a set of links, these models are also treating the network as random, but allow us to test more fine-grained multivariate hypotheses by conditioning on multiple characteristics of the ties and the nodes that are involved in each link at the same time. A popular, and extremely flexible approach to this type of multivariate statistical analysis of networks is the family of exponential random graph models usually abbreviated as ERGMs and pronounced “ergums.”
In this handout we will discuss the first group of strategies focused on randomizing networks via either edge swapping or permutation.
Graph Ensembles
A graph ensemble is just a set of graphs that share some graph level property (like the ones we studied in the very first handout). For instance, they might have the same number of nodes, or the same number of edges, or both, but are different in terms of which particular nodes connect to which.
Note that if an ensemble of graphs has the same number of nodes and edges, they will also be identical with regard to any property that is a function of these two things, like the density.
Usually, what we would want is a graph ensemble that matches the properties that we observe in a graph that corresponds to the network of interest. The idea is to create an ensemble of graphs that are similar to our original data. We can then use the ensemble to test whether some quantity we observe in our data is larger or smaller than we would expect by chance. Here “chance” is simply the probability of observing that value in the ensemble of graphs we created.
As Orsini et al. (2015) note, a simple way to create an ensemble is just by using an edge swapping algorithm on the original graph. Each edge swapping algorithm works by preserving some property of the original graph across each realization, so that all the graphs in the ensemble share that property, while everything else is scrambled.
The Erdos-Renyi Model
In the simplest case, we create an ensemble that preserves the number of nodes and edges of the original graph (and everything that is a function of these, like density and average degree) and randomizes everything else in the ensemble relative to the observed graph.
Let’s see how this would work. First we load up a network, in this case Krackardt’s high tech managers data:
This is the undirected version of the friendship nominations network. Let’s review some graph properties:
We can see that we have \(|V| = 21\), \(|E|=79\), \(d=0.38\), and \(\bar{k}=7.5\).
A rewiring of this graph, which preserves these statistics, goes like this: Pick a random edge, detach it from the vertices that are incident to it, and attach it to a new pair of vertices that are currently disconnected (to avoid multiples), making sure they are distinct vertices (to avoid loops). Do that for some proportion of the edges in the graph.
The result is a new “rewired” graph, that still has the same number of nodes and edges as the original (hence same density and average degree), but with whatever original tie-formation tendencies in the original graph scrambled up.
In igraph we can use the rewire function, along with the each_edge rewiring algorithm to accomplish this.
Let’s say we wanted to rewire up to 50% of the edges of the original network. We would then type:
Which creates a new graph called g.swap1 with 50% of the edges scrambled (note that we set the seed if we want to get the same graph every time we run it).
As we can see, the new graph preserves the density and average degree of the original:
[1] 21[1] 79[1] 0.3761905[1] 7.52381And here’s a side-by-side comparison:
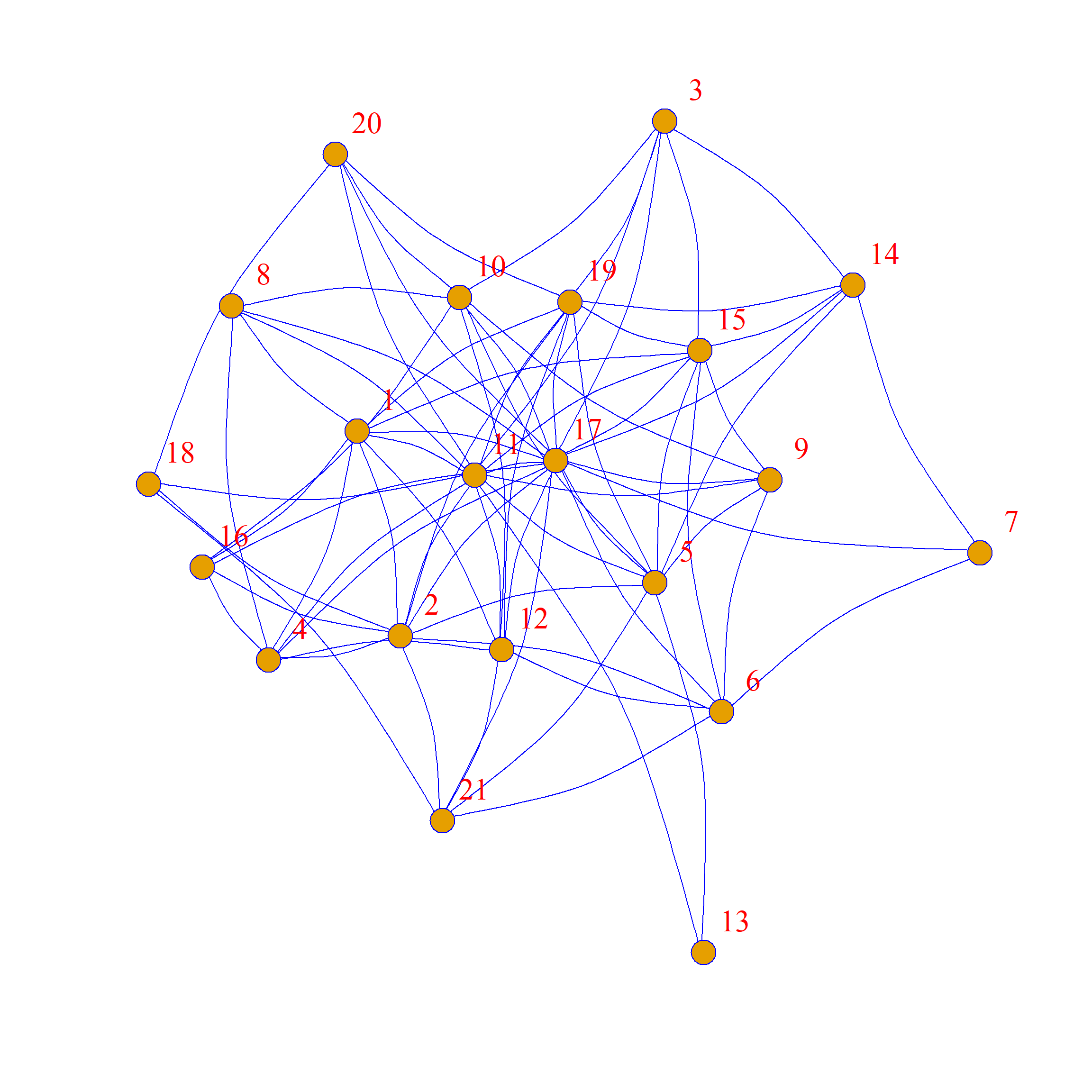
Note that while we preferred some structural features of the original network, the swapped graph has a very different structure!
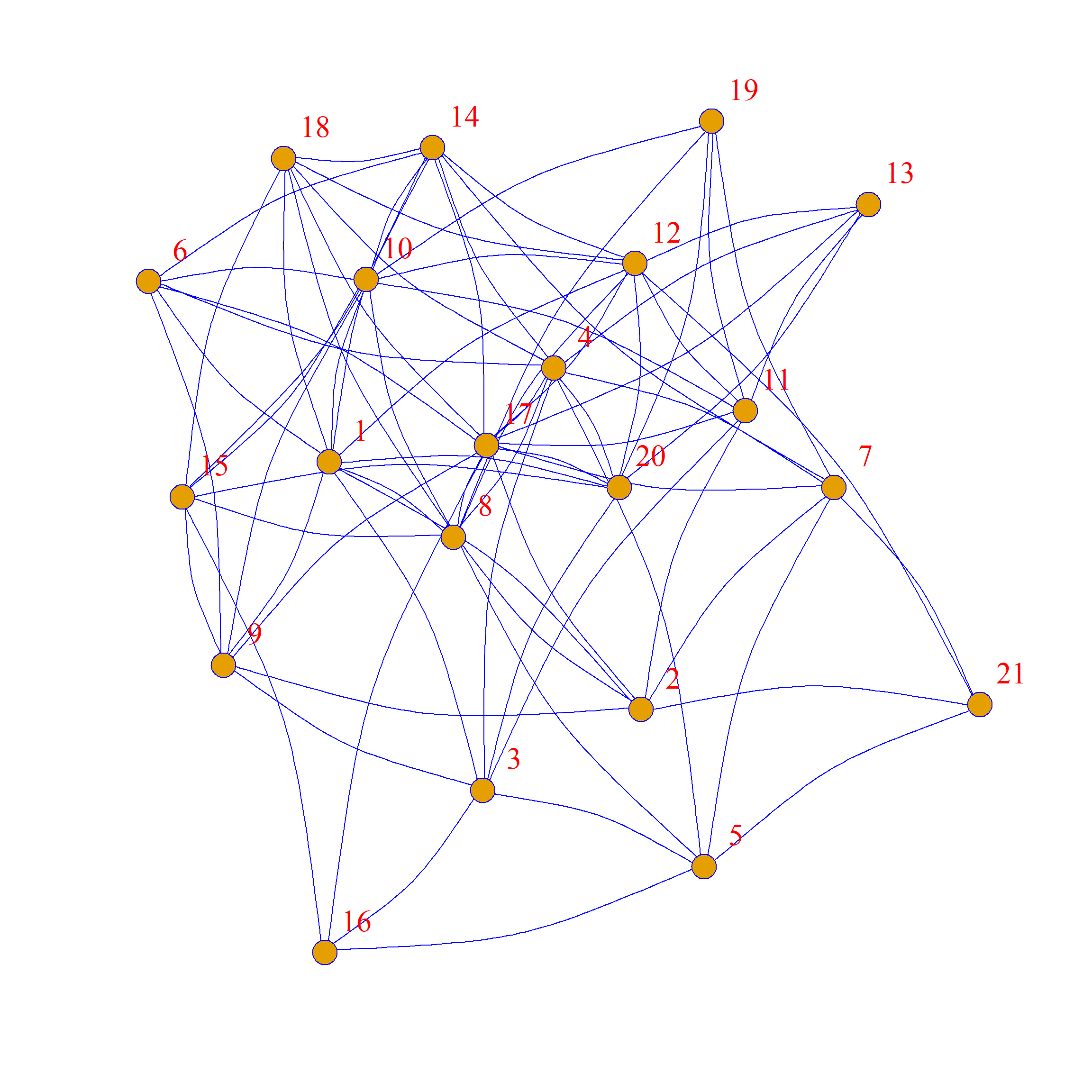
Here are two other graphs that also have the same average degree and density as the original but with 100% of the edges rewired:

One of the reasons why these graphs looks so different from the original is that while these graphs all have the same average degree, the specific degrees of each node are not preserved. This is clear if you compare node 13 in the original graph (which is poorly-connected, with only two friends) to node 13 in the graph to the right of the original, where they now have many (random) friends.
Note that other non-local graph properties (which don’t depend directly on the number of nodes and edges) are also not preserved. For instance, the graph diameter is different across swaps:
[1] 1.569161[1] 1.560091[1] 1.609977[1] 1.573696We will learn how to create graph ensembles that preserve specific node degrees in a bit. But first, let’s see what we can do with graph ensembles.
Null Hypothesis Testing
Remember that one thing we wanted to do is null hypothesis testing; that is, we want to see if something computed in the original graph is more or less than we would expect by chance, given a suitable “null model”, which in our case is a network where the density—and thus expected degree—is preserved but people connect at random (sometimes called an Erdos-Renyi model).
So let’s compute something:
This is Newman’s assortativity coefficient (a.k.a., the modularity) for the nominal category of “Level” telling us that ties are more likely to form between managers of the same level in the company. Is this a “statistically significant” level of assortativity?
Well compared to what? Compared to what we observe in an ensemble of graphs with the same number of nodes, edges, and density!
How do we do that comparison?
First, let’s wrap the density-preserving rewiring into a function:
Now, let’s create an ensemble of 500 edge-swapped graphs, putting them all into a list:
And now we compute our assortativity coefficient in each one of them using sapply:
[1] -0.08 -0.02 -0.07 -0.08 -0.14 -0.11 0.01 0.04 -0.05 0.33 -0.09 0.00
[13] -0.07 0.11 -0.04 0.16 -0.14 0.04 -0.10 -0.04 0.03 -0.13 -0.01 -0.04
[25] -0.20 0.00 -0.10 0.00 0.03 -0.03 -0.05 -0.01 -0.11 -0.02 0.02 -0.06
[37] -0.15 -0.07 -0.21 -0.15 -0.08 -0.21 -0.18 -0.04 -0.02 -0.17 -0.19 -0.06
[49] 0.04 -0.12 -0.11 -0.02 -0.05 -0.15 -0.01 -0.04 -0.11 0.03 0.04 0.09
[61] -0.10 -0.10 -0.10 0.09 -0.09 0.01 -0.12 0.04 -0.13 -0.05 -0.04 -0.08
[73] -0.07 -0.21 -0.09 -0.13 0.08 -0.10 -0.07 -0.02 -0.22 -0.08 -0.06 -0.13
[85] -0.12 -0.10 -0.12 0.03 -0.12 -0.13 -0.10 -0.11 -0.05 -0.07 -0.04 -0.16
[97] -0.07 -0.04 0.04 -0.04Note that the modularity is actually negative in most of these graphs, suggesting that when people form ties at random they are unlikely to magically end up being assortative by level.
So let’s see how our observed value stacks up in the grand scheme:
library(ggplot2)
p <- ggplot(data = data.frame(round(assort, 2)), aes(x = assort))
p <- p + geom_histogram(binwidth = 0.015, stat = "bin", fill = "darkblue")
p <- p + geom_vline(xintercept = assortativity(g, V(g)$level),
color = "red", linetype = 1, linewidth = 1.5)
p <- p + geom_vline(xintercept = 0, linetype = 1,
color = "purple", linewidth = 1.5)
p <- p + theme_minimal() + labs(x = "Q by Level", y = "Freq.")
p <- p + theme(axis.text = element_text(size = 12))
p <- p + annotate("text", x=-0.05, y=47, label= "Zero Point", color = "purple")
p <- p + annotate("text", x=0.06, y=47, label= "Obs. Value", color = "red")
p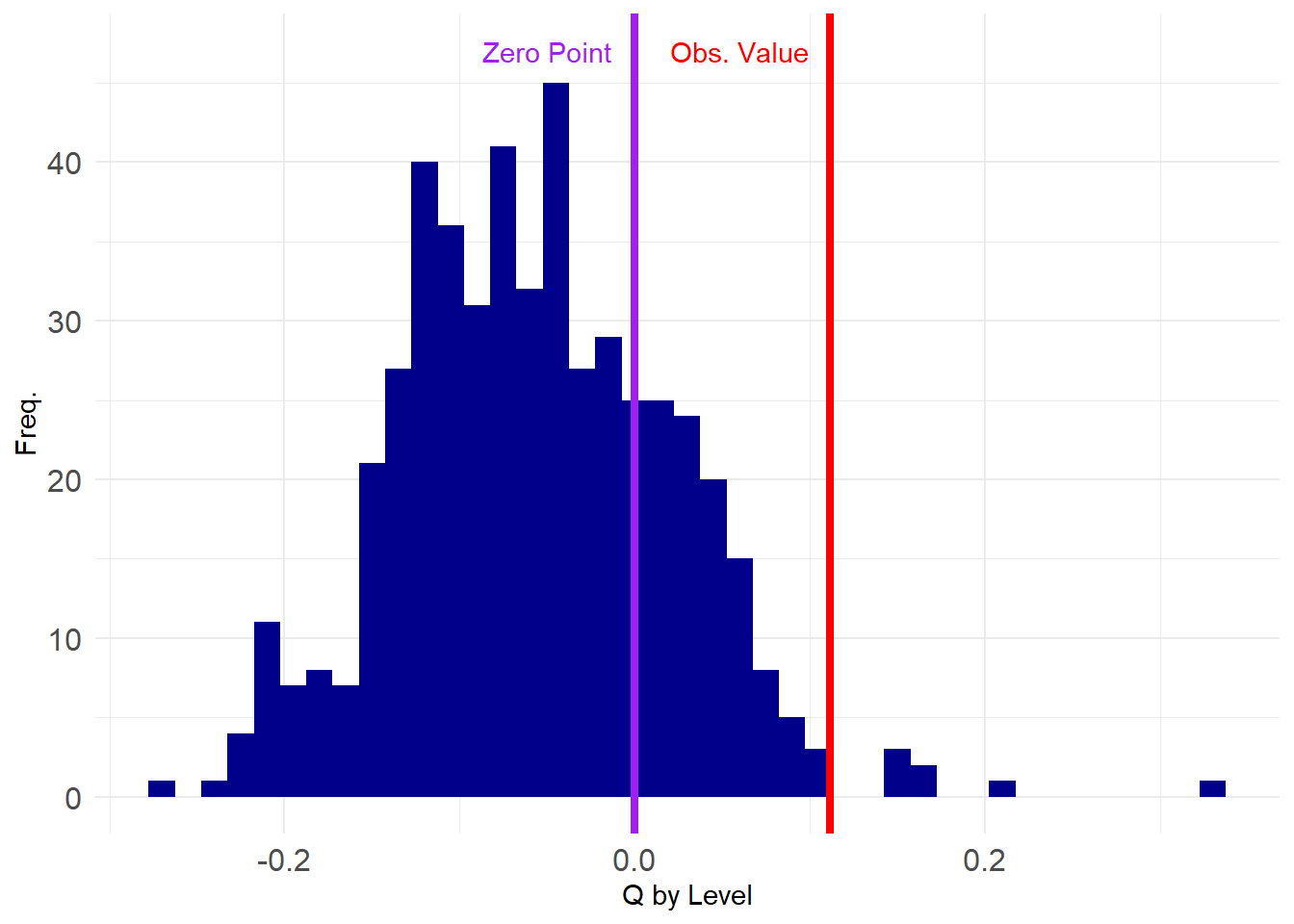
So we can see that only a few of the networks in the ensemble have \(Q\) values higher than the observed one, indicating that what we observed is unlikely to have occurred by chance.
How unlikely? We can just compute the value that corresponds to the 99th percentile of the assortativity distribution from the ensemble and then see if what observe is above that value (corresponding to \(p < 0.01\)).
99%
0.1533994 99%
FALSE We find that our observed value of assortativity by dept is not significant at this level, as the corresponding value in the ensemble distribution is higher than what we observe.
Of course we can also try a less stringent standard for statistical significance, like \(p < 0.05\):
95%
0.0665133 95%
TRUE Which, in this case, is “statistically significant”! This is because the observed value is larger than the corresponding value at the 95th percentile slot of the graph ensemble distribution.
If we wanted to find the actual “p-value” corresponding to our observed value, we would just type the following, which uses the native R function ecdf:
Which yields \(p = 0.014\) for our observed value of assortativity by department, which is good enough to get published.
Note, however, that this is a one-tailed test of significance (Borgatti et al. 2024, 285), this is fine since we usually expect the modularity to be positive which implies a directional hypothesis.
If we wanted a more stringent two-tailed we would need to create a vector with the absolute value of the modularity and use that to construct our test:
Which would fail the statistical significance test by the usual standards (\(p = 0.27\)).
Preserving Degrees
Recall that our swapping function above preserves the expected (average) degree but not the degree of any particular node. This means that the neither the degree sequence nor the degree distribution of the original network is preserved.
This is clear in the following plots:
library(dplyr)
library(tidyr)
deg.dat <- data.frame(Original = degree(g), Swap1 = degree(g.swap1), Swap2 = degree(g.swap2), Swap3 = degree(g.swap3)) %>%
pivot_longer(1:4, names_to = "graph") %>%
mutate(v = sort(rep(1:vcount(g), 4)))
p <- ggplot(data = deg.dat, aes(x = value, group = graph, fill = graph))
p <- p + geom_histogram(binwidth = 0.35)
p <- p + facet_wrap(~ graph, nrow = 4)
p <- p + theme_minimal()
p <- p + theme(legend.position = "none",
axis.text = element_text(size = 12),
strip.text = element_text(size = 14),
axis.title = element_text(size = 14))
p <- p + scale_x_continuous(breaks = c(1:18))
p <- p + labs(x = "", y ="")
p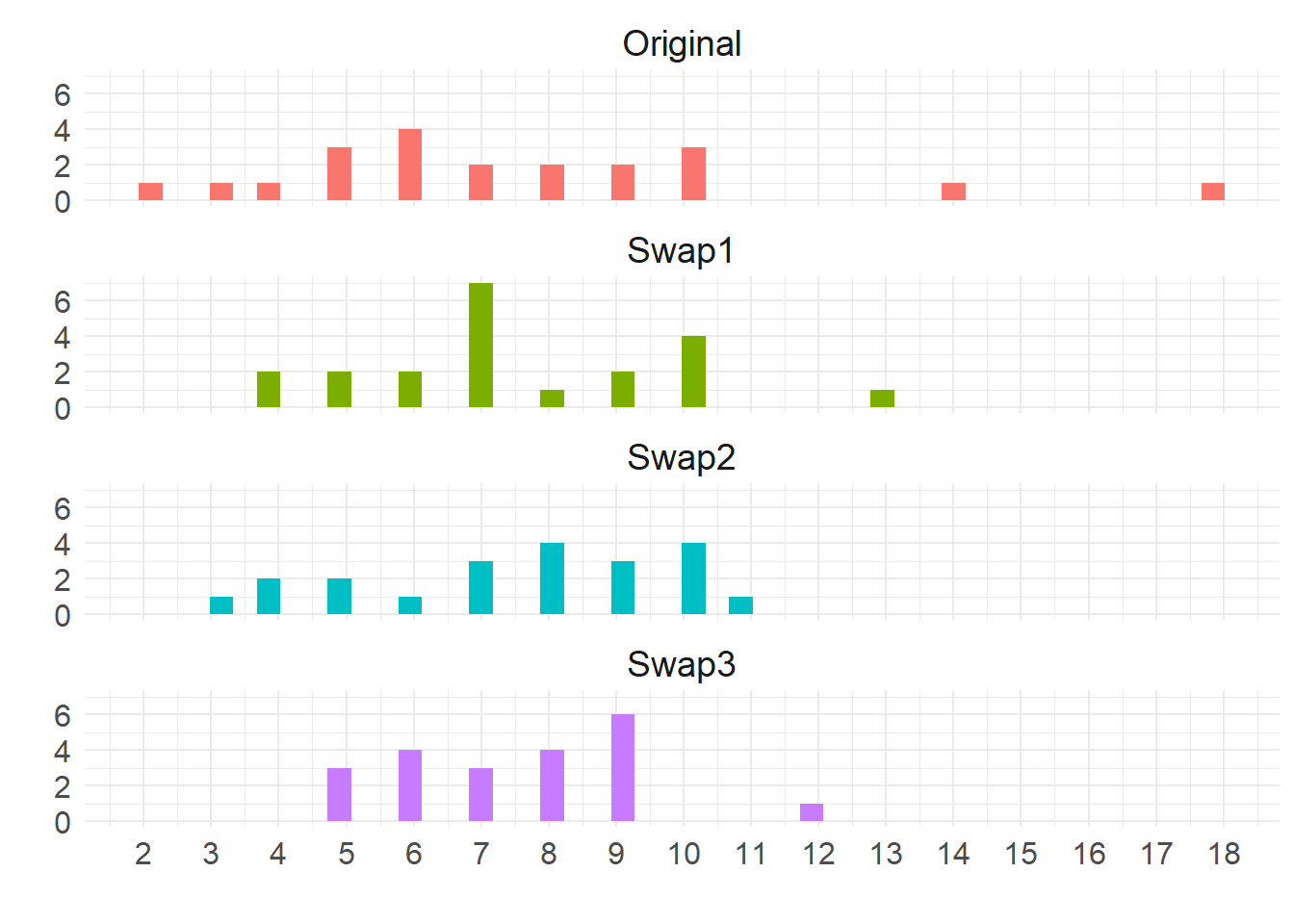
The top shows the original degree distribution, which is different from the ones in the swapped graphs. In fact, it is clear that the swapped degree distribution get rid of extreme high degree nodes and pull everyone to the middle (Erdos-Renyi graphs degrees tend toward a Poisson distribution).
So it could be that the plain average degree (Erdos-Renyi) preserving model is too simplistic to use as a plausible null model. A better model is one that would preserve the degrees of each node in the ensemble but make every connection otherwise random.
In igraph there is a trusty function called keeping_degseq—which is used alongside the more general function rewire we used earlier—that allows us to scramble the edges in a graph while keeping the degrees of each node the same as the original.
The basic idea is to sample a pair of edges connecting vertices \(a\) and \(b\) and \(c\) and \(d\) respectively, delete them, and create two new edges (if they don’t currently exist) between vertices \(a\) and \(c\) and between \(b\) and \(d\), repeating this process niter number of times. As it is clear, this randomizes connections but keeps the number of edges incident to each node the same (Maslov and Sneppen 2002).
Let’s see how it works:
[1] 9 10 6 7 10 7 3 5 6 8 14 8 2 6 9 5 18 4 10 5 6 [1] 9 10 6 7 10 7 3 5 6 8 14 8 2 6 9 5 18 4 10 5 6We can see that the edge-swapping algorithm creates a new graph with exactly the same degree sequence as the original.
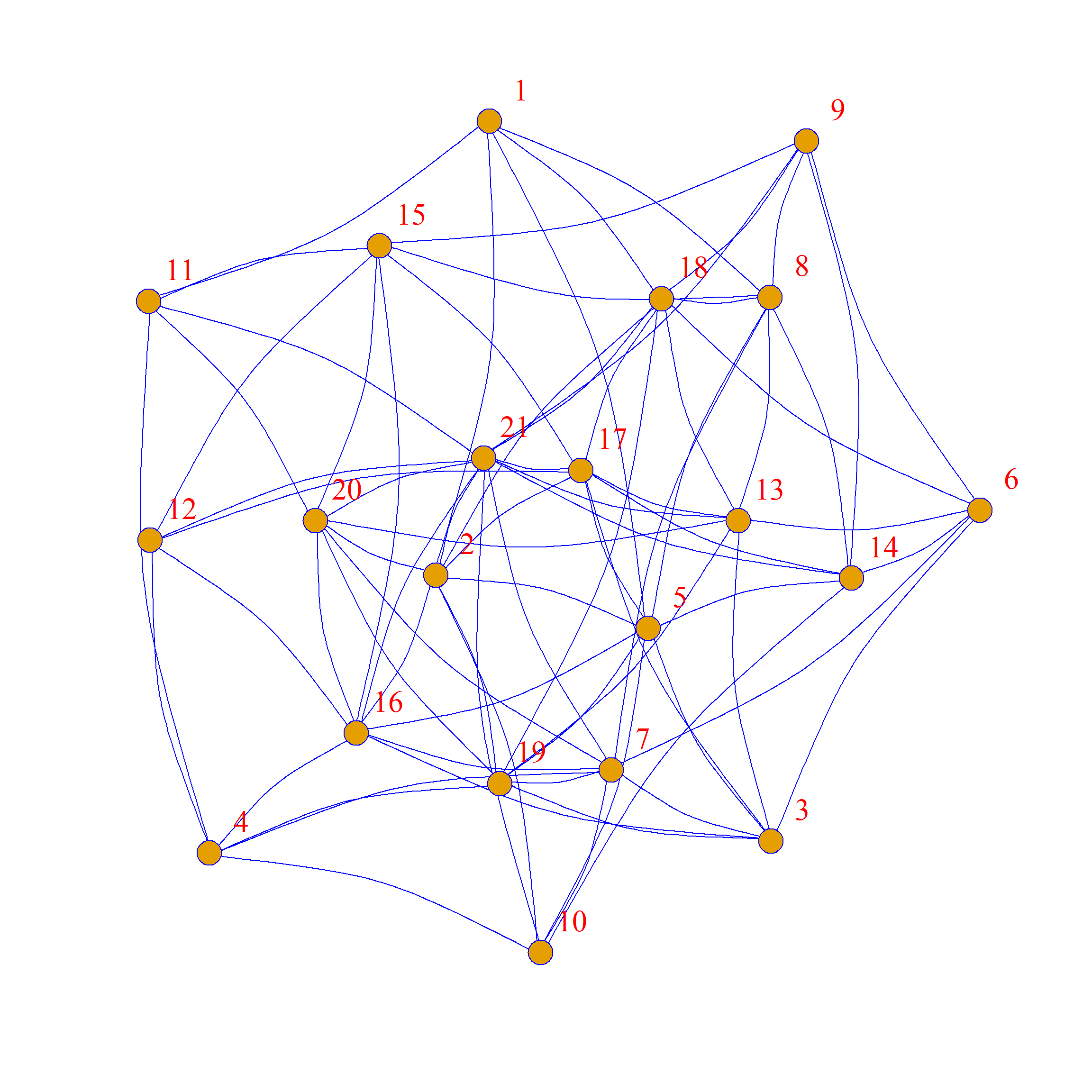
Here they are side-by-side:
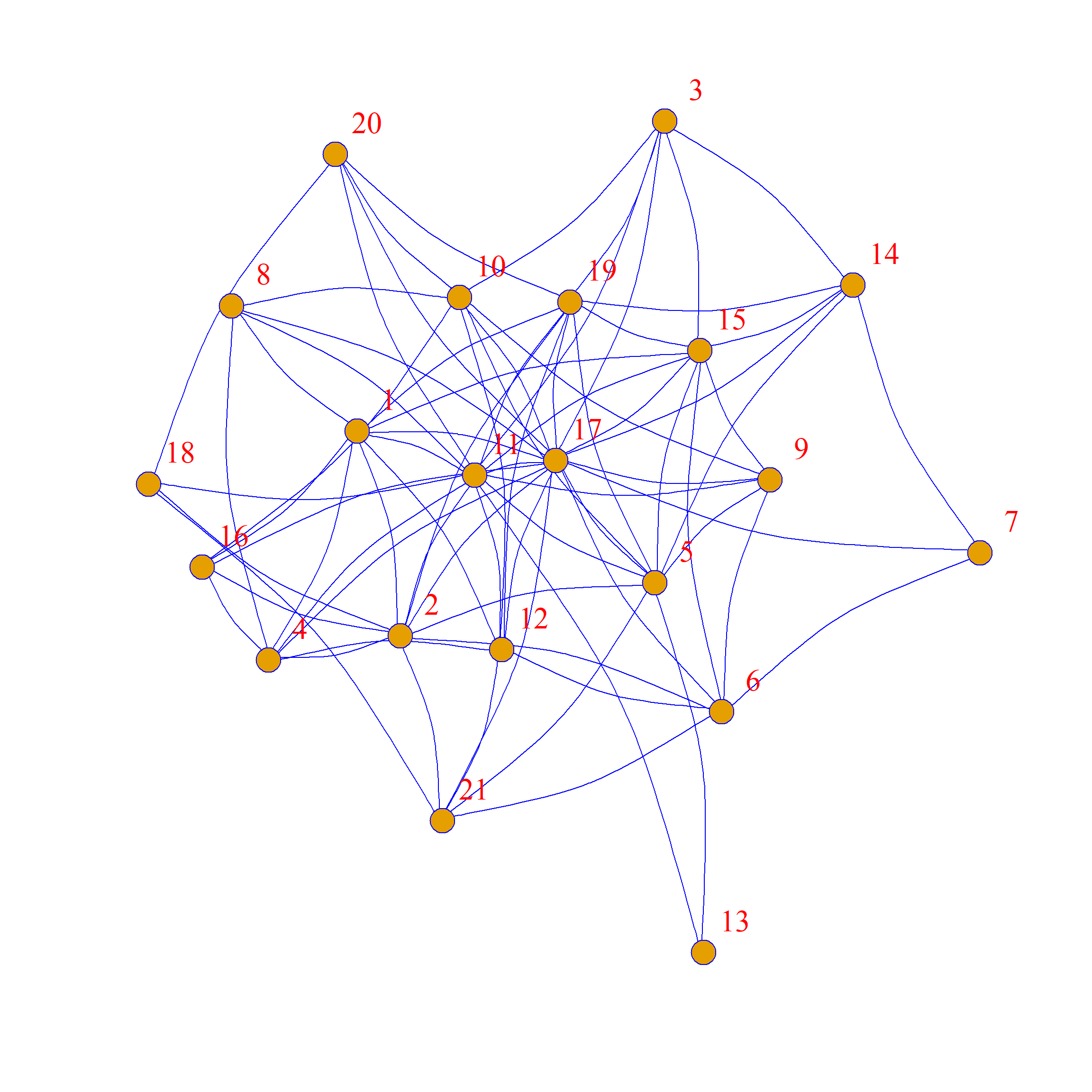
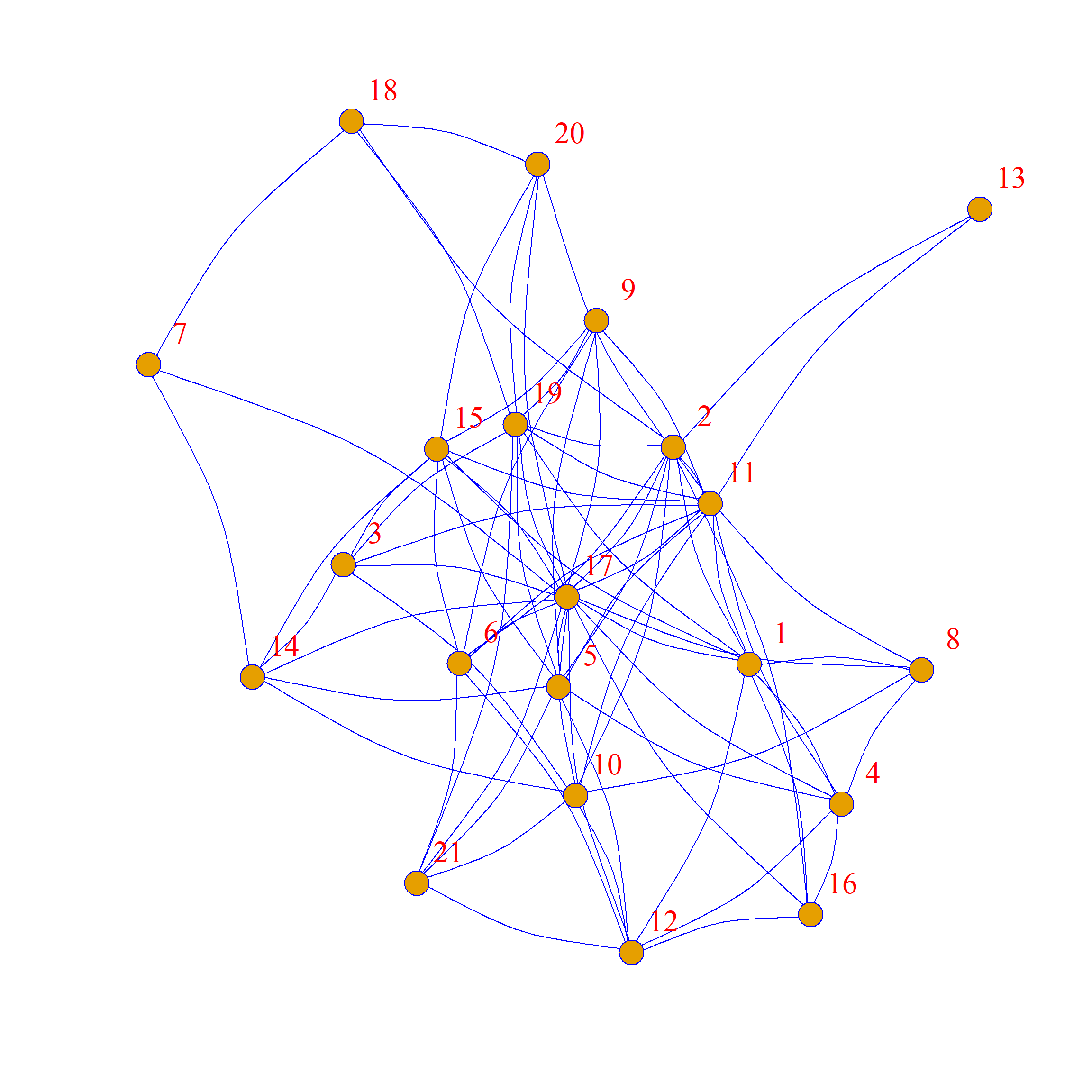
As we can see, the network structure is definitely different between these two graphs, but each node has the same levels of connectivity in each.
So now we can use our more stringent null model to test our previous hypothesis: Is the observed level of assortativity by level more than we would observe in the same network where everyone keeps their degree centrality but everything is random?
Let’s find out.
First, let’s wrap the degree-preserving swap into a function:
Then let’s create our graph ensemble this time using 500 graphs:
And see where our observed value falls in the distribution:
assort <- sapply(G2, assortativity, values = V(g)$level)
library(ggplot2)
p <- ggplot(data = data.frame(round(assort, 2)), aes(x = assort))
p <- p + geom_histogram(binwidth = 0.08, stat = "bin", fill = "darkblue")
p <- p + geom_vline(xintercept = assortativity(g, V(g)$level),
color = "red", linetype = 1, linewidth = 1.5)
p <- p + geom_vline(xintercept = 0, linetype = 1,
color = "purple", linewidth = 1.5)
p <- p + theme_minimal() + labs(x = "Q by Level", y = "Freq.")
p <- p + theme(axis.text = element_text(size = 12))
p <- p + annotate("text", x=-0.04, y=170, label= "Zero Point", color = "purple")
p <- p + annotate("text", x=0.07, y=170, label= "Obs. Value", color = "red")
p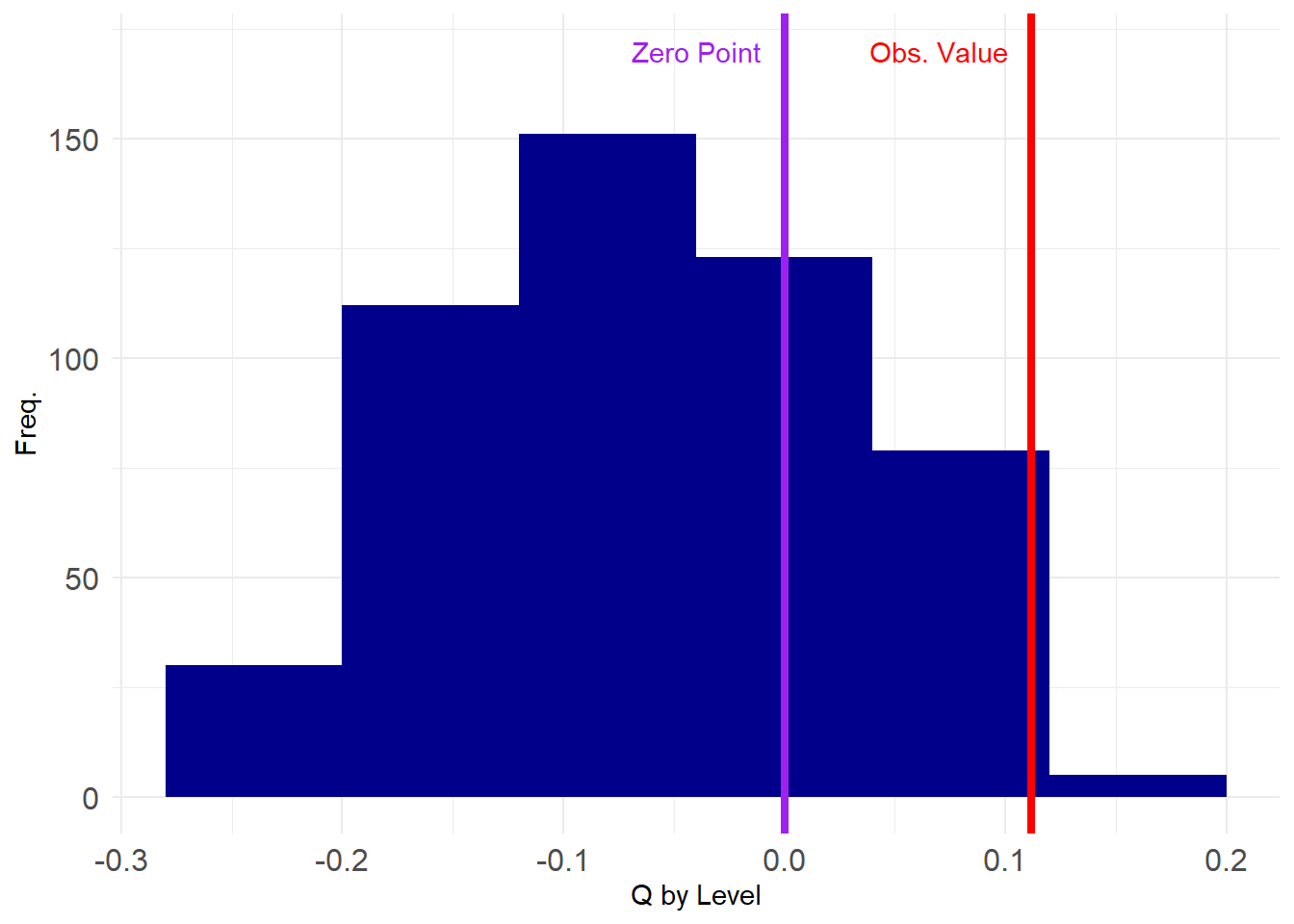
Note that the values are much more constrained this time around, falling within specific ranges. We can test our hypothesis the same way as before:
95%
0.05136546 95%
TRUE Which tells us that after account for node degree differences, the observed value we observed is still significantly larger than we would have observed by chance using conventional cutoffs.
Indeed, the p-value of the estimate is:
Which is pretty good. Maybe our paper will be published after all!
But oh no, some reviewer who doesn’t know what they are talking about asked for a two-tailed test:
It’s a rejection after all.
Cross-Network Correlation Using Permutation
Consider the case where we measure two or more ties on the same set of actors. In that case, we could entertain hypotheses of the form: Is having a tie of type \(A\) positively or negatively correlated with a tie of type \(B\)?
We can use an approach similar to the edge-swapping strategy to answer this question, since a bivariate correlation between ties between two networks is just like the univariate statistics we computed earlier (in that case the modularity, but it could been any network level statistic like the diameter or centralization).
Let’s see an example. Suppose we have a hypothesis that the relation of “friendship” should be correlated to that of “advice”; that is, people are more likely to seek advice from friends.
The Krackhardt High-Tech Managers data contains network information on both the advice and friendship relations between the actors. Let’s load up the advice network:
And extract the corresponding adjacency matrices:
The correlation between these two ties is then:
Which is obtained by “vectorizing” the matrices and computing the Pearson correlation between the dyad vector (of length \(21 \times 21 = 441\)) corresponding to friendship ties and the dyad vector corresponding to advice ties.
Here, we see that there is a positive correlation between the two (\(r = 0.26\)) suggesting people tend to seek advice from friends (or befriend their advisors/advisees, as correlations don’t imply directionality).
However, is this correlation larger than we would expect by chance? For that, we need to know the range of correlations that would be obtained between on of the networks (e.g., advice) and a suitably randomized version of the other (e.g., friendship).
The “permutation” approach (Borgatti et al. 2024, chap. 14)—sometimes referred to by the less-than-wieldy name of the Quadratic Assignment Procedure (QAP) (Krackhardt 1988)—allows us to do that.
Recall from our discussion of blockmodeling that a permutation of an adjacency matrix is just a reshuffling of its rows and columns.
For instance the original adjacency matrix of the Krackhardt Managers friendship nomination network is shown in Table 1 (a).
We can permute the rows and columns of the matrix by randomly sampling numbers between 1 and 21 (the number of nodes in the network) and re-ordering the rows and columns of the matrix according to this new vector:
[1] 21 9 8 14 2 20 16 7 5 18 17 1 12 10 19 4 6 11 15 3 13The new permuted matrix is shown in Table 1 (b).
Table 1: An adjacency matrix and a permuted version
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Note that when we lose the labels on the nodes the permuted matrix contains that same information as the original, but scrambles the node labels.
So, in contrast to the edge swapping approach, which preserves some graph characteristics but loses others, in the permutation approach, every graph-level characteristic stays the same:
[1] 6 6 5 6 10 5 5 3 10 4 18 9 8 8 10 7 7 14 9 6 2 [1] 9 10 6 7 10 7 3 5 6 8 14 8 2 6 9 5 18 4 10 5 6 [1] 18 14 10 10 10 9 9 8 8 7 7 6 6 6 6 5 5 5 4 3 2 [1] 18 14 10 10 10 9 9 8 8 7 7 6 6 6 6 5 5 5 4 3 2[1] 1.569161[1] 1.569161[1] 0.21[1] 0.21A function that takes an undirected graph as input, permutes the corresponding adjacency matrix and returns the new graph as output looks like:
So to get a p-value for our cross-tie correlation all we need to do is to compute the correlation between the original advice network and a set of permuted graphs of the friendship network.
First, we create a 1000 graph ensemble of permuted friendship networks:
Then we write a function for computing the correlation between two networks:
And now we compute our correlation vector showing the first 100 elements:
[1] 0.12 -0.12 0.10 -0.06 0.14 0.02 -0.02 -0.04 0.06 0.12 0.08 0.08
[13] 0.08 -0.02 0.22 0.04 -0.12 0.06 -0.02 0.02 0.12 0.00 0.16 0.06
[25] 0.28 0.16 0.10 0.08 0.00 0.04 0.02 0.16 0.16 0.10 0.08 0.10
[37] 0.02 0.12 0.02 0.16 0.02 0.02 -0.02 0.12 0.10 0.10 0.08 0.08
[49] 0.14 -0.06 0.04 -0.02 -0.06 0.12 -0.02 0.20 -0.02 0.08 -0.10 0.06
[61] 0.00 0.04 0.14 0.06 -0.04 0.04 -0.02 0.10 -0.02 0.06 0.12 -0.08
[73] 0.04 0.06 0.14 0.12 0.08 0.08 0.16 -0.06 0.02 0.06 0.22 0.14
[85] -0.04 0.06 0.00 -0.10 0.16 -0.08 0.08 0.16 0.04 0.02 0.08 -0.02
[97] 0.16 0.16 -0.08 0.12And here’s a plot of where our estimated value sits on the grand scheme of things:
library(ggplot2)
p <- ggplot(data = data.frame(corrs), aes(x = corrs))
p <- p + geom_histogram(binwidth = 0.025, stat = "bin", fill = "darkblue")
p <- p + geom_vline(xintercept = r,
color = "red", linetype = 1, linewidth = 1.5)
p <- p + geom_vline(xintercept = 0, linetype = 1,
color = "purple", linewidth = 1.5)
p <- p + theme_minimal() + labs(x = "Friendship/Advice Correlation", y = "Freq.")
p <- p + theme(axis.text = element_text(size = 12))
p <- p + annotate("text", x=-0.04, y=150, label= "Zero Point", color = "purple")
p <- p + annotate("text", x=0.22, y=150, label= "Obs. Value", color = "red")
p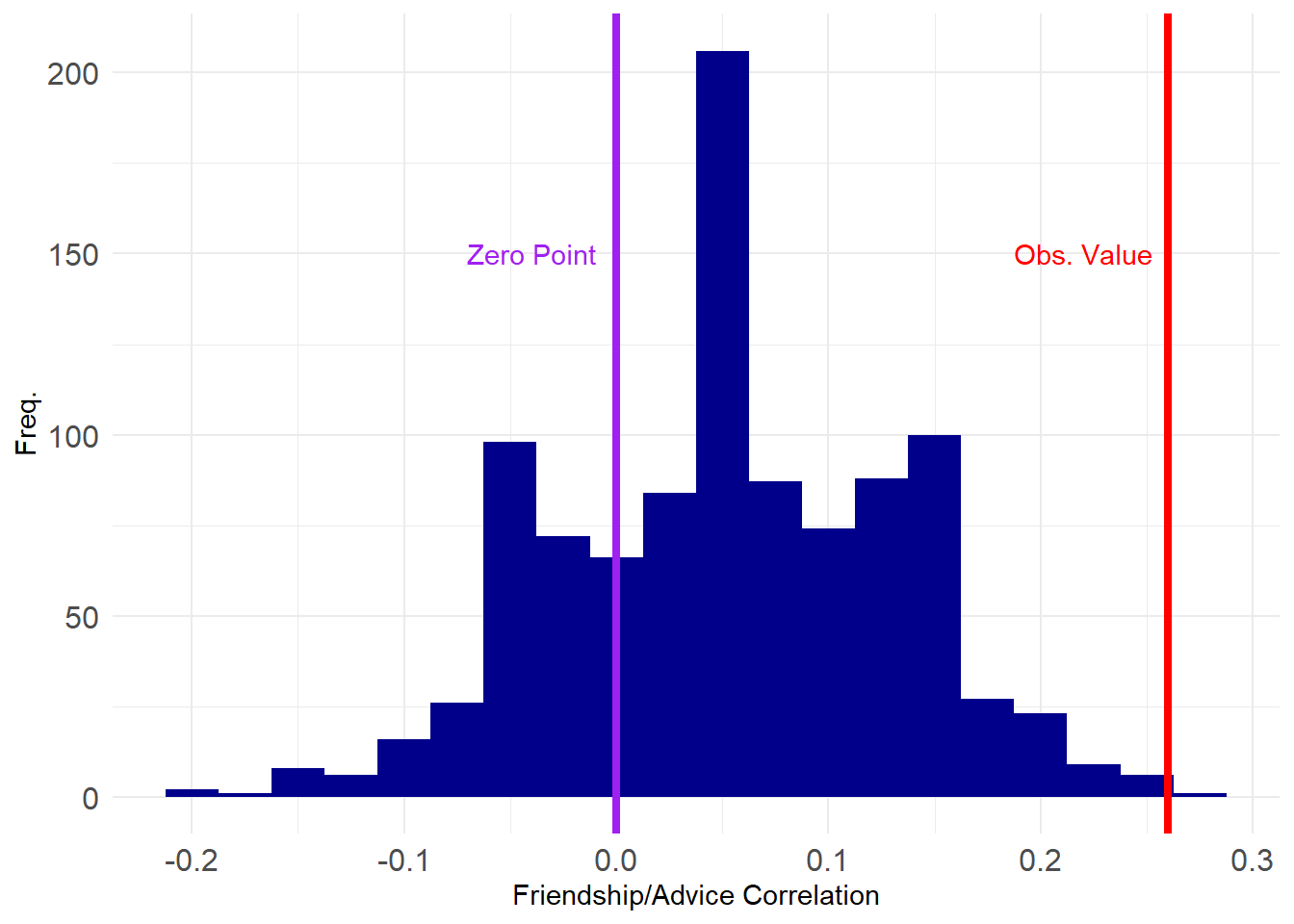
This looks pretty good, with only a tiny proportion of the correlations exceeding the observed value.
We can check our p-value like before:
99%
0.22 99%
TRUE [1] 0.001Which shows that the correlation between advice and friendship is significant at the \(p = 0.001\) level (\(p<0.01\)).
Note that the result is also statistically significant using a two-tailed test:
Cross-Network Regression Using Permutation
The permutation (QAP) approach can be extended to considering more than two network variables at the same time, which moves us into multivariable territory. The Krackhardt Managers data also contains information on formal links in the organization in the form of a graph of unidirectional “reports to whom” network, shown below:
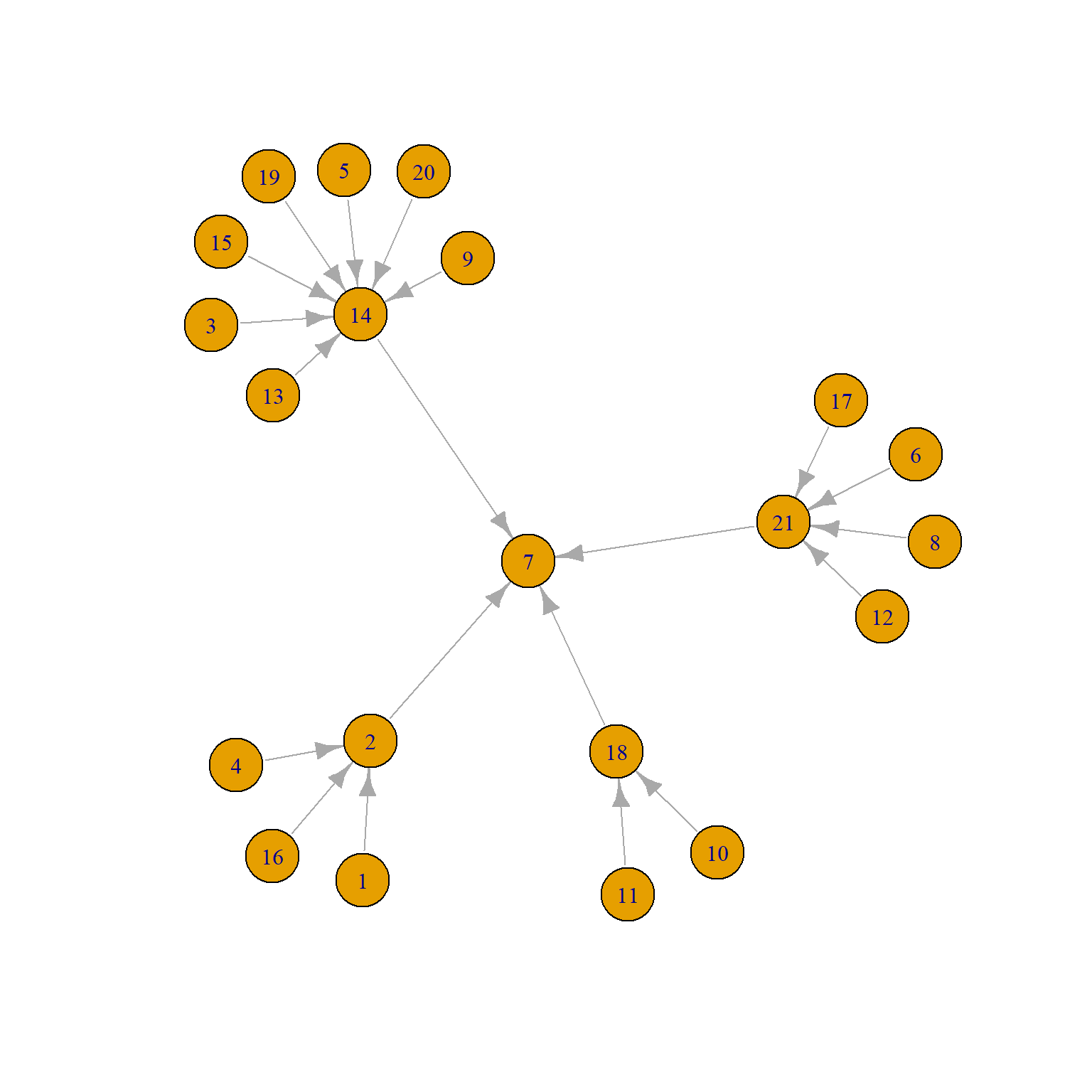
We can see that there are four middle managers (2, 14, 18, and 21) all of whom report to the top manager (7).
So let’s say we wanted to predict advice ties from friendship ties while adjusting for the present of formal reporting ties. We could just run a regression like this:
A.r <- as.matrix(as_adjacency_matrix(
as_undirected(ht_reports, mode = "collapse")))
ht.dat <- data.frame(frs = as.vector(A.f), adv = as.vector(A.d), rep = as.vector(A.r))
reg.res <- lm(adv ~ frs + rep, data = ht.dat)
summary(reg.res)
Call:
lm(formula = adv ~ frs + rep, data = ht.dat)
Residuals:
Min 1Q Median 3Q Max
-0.7748 -0.5475 0.2252 0.4525 0.4525
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.54750 0.02714 20.172 < 2e-16 ***
frs 0.22727 0.04535 5.011 7.88e-07 ***
rep 0.31614 0.07572 4.175 3.60e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4509 on 438 degrees of freedom
Multiple R-squared: 0.1033, Adjusted R-squared: 0.09925
F-statistic: 25.24 on 2 and 438 DF, p-value: 4.22e-11Which shows that friendship has a statistically significant positive effect on being ties via an advice tie, net of the formal hierarchical link, which also has a positive effect.
Of course, if you know anything about classical inference, you know the standard errors and associated t-statistics are useless, because the “cases” in the regression above are dyads, and they are not independent from one another because they form…a network!
So we can use the permutation approach to get more credible p-values like we did with the correlation, turning the above into a “QAP Regression.”
The basic idea is just to run the regression many times, while permuting the outcome variable; this would produce a distribution of coefficient estimates, and we can select the p-value non-parametrically like we did earlier.
Here’s a function that will run a regression and collect the coefficients:
We now create a graph ensemble of 1000 permuted advice networks:
And now we run the regression on our 1000 strong ensemble of permuted advice network graphs:
reg.list <- lapply(G4, run.reg,
indvars = c("frs", "rep"), dat = ht.dat)
betas <- as.matrix(do.call(rbind, reg.list))
colnames(betas) <- c("Int.Est", "Fr.Est", "Rep.Est")
head(betas) Int.Est Fr.Est Rep.Est
[1,] 0.6346486 0.02616358 0.14965327
[2,] 0.6446012 0.01130525 0.09861561
[3,] 0.6641230 0.01258719 -0.12167530
[4,] 0.6366876 0.12453946 -0.26141124
[5,] 0.6378383 0.03154367 0.09323552
[6,] 0.6100193 0.17449454 -0.16471601And now we compute the p-values as before and gather them into a table:
p.vals <- c(1 - ecdf(abs(betas[, 1]))(reg.res$coefficients[1]),
1 - ecdf(abs(betas[, 2]))(reg.res$coefficients[2]),
1 - ecdf(abs(betas[, 3]))(reg.res$coefficients[3])
)
z.scores <- round(abs(qnorm(p.vals)), 3)
z.scores[1] <- "--"
reg.tab <- data.frame(reg.res$coefficients, z.scores, p.vals)
rownames(reg.tab) <- c("Intercept", "Friend Tie", "Formal Tie")
names(reg.tab) <- c("Estimate", "z-score", "p-value")
kbl(reg.tab[c(2:3), ], rownames = TRUE, format = "html", digits = 3,
caption = "Predictors of Advice Ties") %>%
column_spec(1, italic = TRUE) %>%
kable_styling(full_width = TRUE,
bootstrap_options = c("hover",
"condensed",
"responsive")) | Estimate | z-score | p-value | |
|---|---|---|---|
| Friend Tie | 0.227 | 2.257 | 0.012 |
| Formal Tie | 0.316 | 2.226 | 0.013 |
Which shows that indeed friendship and formal reporting ties are both statistically significant predictors of advice ties after accounting for network interdependencies.